BRIDGE / BGCC:Behavior-Guided Candidate Calibration for Multimodal Recommendation
这篇 2026-05-21 公开的 arXiv:2605.22073 论文可以译为《面向多模态推荐的行为引导候选校准》。作者是 Zesheng Li、Chengchang Pan、Honggang Qi,一作主机构为 University of the Chinese Academy of Sciences,代码入口已核验到 GitHub 仓库。它的阅读重点不是“又提出一个多模态推荐编码器”,而是把内容证据、行为证据和候选范围三者的权限重新分开:多模态 backbone 负责形成候选几何,训练期共用户行为只在候选集合内部给出有符号残差校准。
1. 背景和问题
多模态推荐长期面对一个很现实的矛盾:图像、标题、描述、品牌、类目等内容特征确实能缓解交互稀疏,尤其是对长尾商品、冷启动内容和视觉主导场景;但这些内容特征一旦被当成全局排序证据,就很容易把“看起来相似”误当成“这个用户会喜欢”。在电商和内容推荐里,同一类目、相似封面、相似标题的 item 可能对应完全不同的消费意图。一个用户买婴儿车以后可能继续看安全座椅,也可能完全不想看另一个婴儿车;一个用户看某类运动装备,下一步偏好可能由品牌、价位、尺码、历史复购和季节共同决定,而不仅是视觉特征。传统多模态推荐方法通常把内容信号作为更强表征的一部分,默认图像、文本和 ID 表征越一致,排序越可靠。BRIDGE 这篇论文的出发点正是质疑这个默认假设。
论文把问题拆成两个诊断。第一,直接跨模态一致性存在有效区间。作者在 Amazon Baby 上做了 direct-consistency diagnostic:不用直接一致性时 Recall@20 是 0.0922;适度一致性设置下,contrastive loss 权重 0.01、similarity 权重 0.3、UI cosine 能把 Recall@20 提到 0.1024;但更强的一致性设置,contrastive loss 权重 0.1、similarity 权重 1.0,Recall@20 反而降到 0.0836。这个结果说明内容视图之间的对齐不是单调收益。轻度对齐能让视觉、文本和协同行为共享一部分结构,过强对齐却会压掉推荐任务真正需要的私有差异。推荐最终决定经常发生在一个很窄的候选集合里,候选之间差别细到可能只是品牌、价位、场景或历史共现模式,强行让所有模态一致会削弱这些局部差异。
第二,频率诊断显示低频和高频承担不同角色。BRIDGE 所说的频率不是图拉普拉斯特征值意义上的图频率,而是图平滑后的表示矩阵做奇异值分解后得到的 representation-spectral ordering。领先的低频带包含更多共享结构,跨视图 cosine 更高;后面的高频带跨视图一致性更弱,但保留更多局部排序信息。论文在 Figure 2 中说明,低频更像“多模态共同认可的语义邻域”,高频更像“在相近物品之间区分用户偏好的残差信息”。这正好解释了为什么单纯追求视图一致性会出问题:它提高了共享语义,却可能抹平最后排序所需要的近邻差异。
从推荐链路看,BRIDGE 的问题定义非常工程化。线上系统通常先由召回、多模态语义匹配、粗排或图模型生成候选,再由精排、重排、规则和业务约束决定最终曝光。内容特征适合扩大候选覆盖或改善候选空间,但不一定应该全局改写每个 item 的分数。若把内容相似度作为全局残差,热门 item、视觉模板相似 item 和重复内容会获得过强优势;若完全不用内容,稀疏用户和长尾 item 又缺少侧信息。论文提出的核心问题可以写成一句话:内容证据什么时候有资格改变最终排序?BRIDGE 的回答是:只有当 base backbone 已经把 item 放进候选集合,并且训练期行为证据支持该 item 与用户历史有更强关系时,内容相关的残差才应该介入。
这也是论文和很多多模态融合工作的差别。过去的方法往往问“如何融合图像、文本、ID 和用户-物品图”,BRIDGE 问的是“融合后的证据是否应该影响这个候选的最终位置”。前者更像 representation learning,后者更像 ranking authority control。BRIDGE 把多模态 backbone、行为证据和候选作用域拆成三层:DFGE 负责生成频率感知的多模态基础分数;BEN 从训练交互图里估计共用户行为支持;CRI 只在候选集合内把 BEN 的支持转成有符号残差。这样做的好处是可诊断:如果候选集质量差,应检查 backbone;如果残差过强,应检查 BEN 或候选范围;如果全局排序被改写,应检查 CRI 的 scope,而不是把所有问题都归咎于一个黑盒融合向量。
2. 方法
2.1 总体结构:候选几何和候选内校准分离
BRIDGE 的最终分数由基础分数和候选内行为残差组成。基础分数来自多模态图编码器,它读取用户-物品交互图、item ID 表征、视觉特征和文本特征,形成全量 item 空间里的 base ranking。行为残差来自训练期共用户行为图,它不参与全量目录的自由加分,而是只在 base score 选出的候选集合内部生效。这个结构看起来像普通 residual reranking,但论文真正强调的是 residual 的授权边界:候选外 item 只通过 backbone 学习,候选内 item 才能被行为证据局部上调或下调。
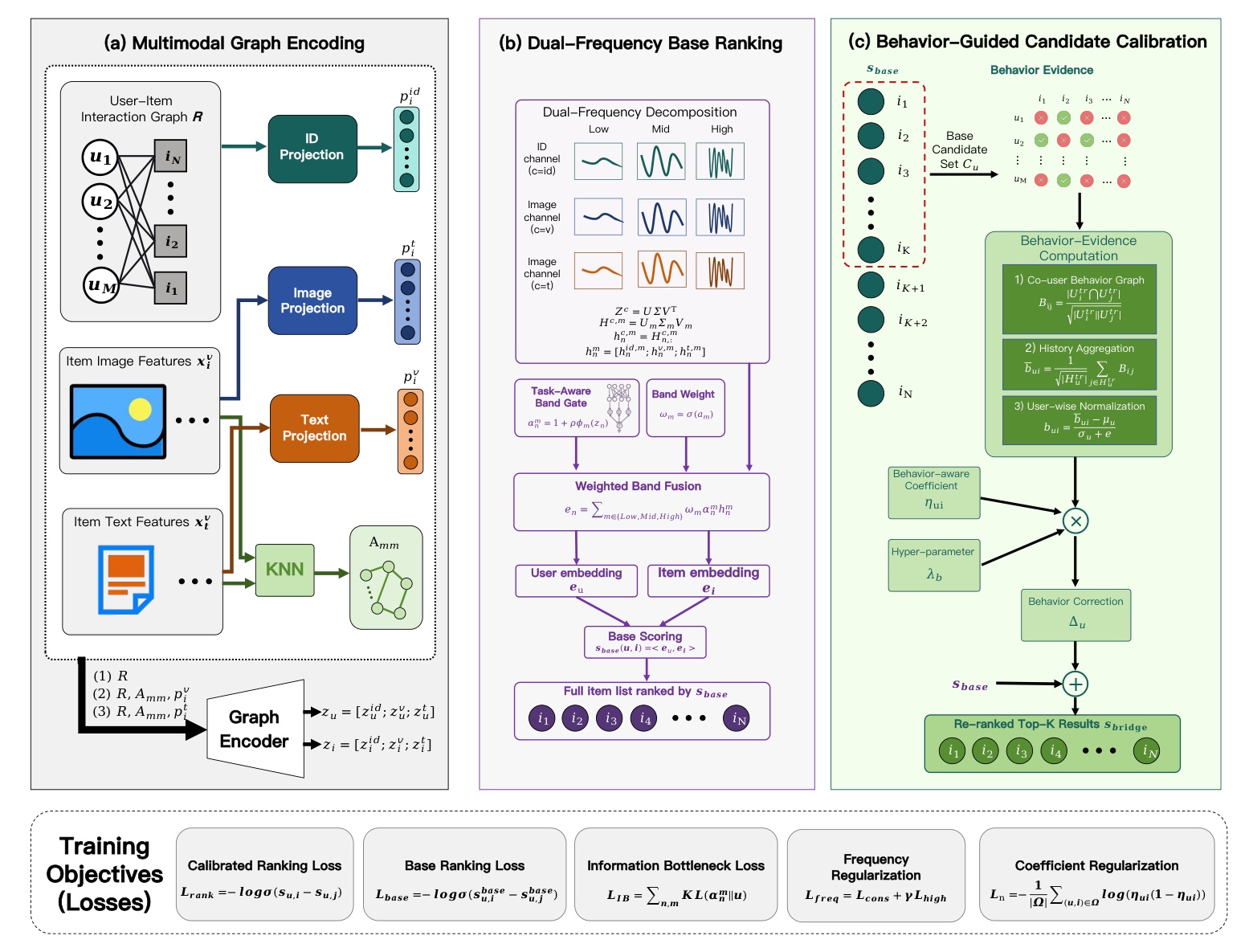
Figure 1 是理解 BRIDGE 的主图。左侧的 Multimodal Graph Encoding 将用户-物品交互图、图像特征和文本特征分别投影到可传播空间,并结合内容 KNN 图得到 item 侧结构;中间的 Dual-Frequency Base Ranking 对每个通道做频带拆分、task-aware band gate 和 weighted band fusion,输出用户与 item 的 base embedding;右侧的 Behavior-Guided Candidate Calibration 先由 base score 得到候选集合,再用行为证据计算一个 correction,最后只在候选内把它加到基础分数上。图底部列出的 calibrated ranking loss、base ranking loss、information bottleneck loss、frequency regularization 和 coefficient regularization 也说明,这不是一个单损失的 reranker,而是把候选几何、频带结构和残差作用域一起约束。读这张图时要特别注意箭头顺序:内容 evidence 先定义候选空间,行为 evidence 再决定局部 correction;如果把二者混成一个全局分数,就失去了论文最重要的控制变量。
论文的问题形式可以先从隐式反馈推荐写起。设用户集合为 $U$,物品集合为 $I$,观测到的隐式反馈为 $R=\{(u,i)\mid u\in U,i\in I\}$。每个 item 有视觉特征 $x_i^v$ 和文本特征 $x_i^t$,用户 $u$ 的历史交互集合记为 $H_u$,与 item $i$ 交互过的用户集合记为 $U_i$。常规 BPR 训练目标是让正样本 $i$ 的分数高于负样本 $j$:
符号解释:$s(u,i)$ 是用户 $u$ 对 item $i$ 的排序分数,$i$ 是观测正样本,$j$ 是采样负样本,$\sigma(\cdot)$ 是 sigmoid。大多数多模态推荐方法会把 $s(u,i)$ 直接定义为融合后的用户和 item 表征内积。BRIDGE 则把最终分数显式拆开:
符号解释:$s_{\mathrm{base}}(u,i)$ 由频率感知的多模态 backbone 给出,$\Delta_{\mathrm{bridge}}(u,i)$ 是行为引导的候选内残差。这个拆分非常关键,因为它让“候选生成”和“候选内校准”成为两个可单独分析的模块。若某个相关 item 根本没有进入 base top-$K$,残差没有权限凭空救回;若一个 item 进入候选但行为证据低于该用户平均水平,残差也可以是负的,起到 demotion 而不是只会 boost。
2.2 DFGE:双频图证据编码器
DFGE 的第一步是多通道图编码。论文把 ID、视觉、文本三个通道分别投影到相同维度。对通道 $c\in\{\mathrm{id},v,t\}$,输入状态可以理解为用户偏好表与 item 特征投影的拼接:
符号解释:$P_u^c$ 是通道 $c$ 下的用户可学习偏好表,$W_c$ 是该通道的线性投影矩阵,$x_i^c$ 是 item 的通道特征;ID 通道中的 item 侧特征是可学习 ID embedding。随后在对称归一化的用户-物品邻接矩阵 $\hat A_{ui}=D^{-\frac12}A_{ui}D^{-\frac12}$ 上做 $L=2$ 轮消息传播:
符号解释:$H^{c,(\ell)}$ 是第 $\ell$ 层传播后的节点表示,$Z^c$ 是把各层状态相加后的通道表示。论文还用内容特征构建缓存的多模态 item 图,图像和文本都可用时采用 $0.1A_v+0.9A_t$ 的加权 item graph,$K=10$,再做一层 item 侧平滑。这个设计说明 DFGE 并不是只靠用户-物品图传播,它同时把内容近邻作为 item 之间的结构先验,但把这个先验放在 backbone 内部,而不是直接拿内容相似度改写最终分数。
公式审计上,DFGE 最核心的是频带分解。对图平滑后的通道矩阵 $Z^c$ 做奇异值分解:
然后把奇异方向按能量顺序切成 $M$ 个连续频带,第 $m$ 个频带重构为:
符号解释:$U_m$、$\Sigma_m$、$V_m$ 是第 $m$ 个频带对应的奇异向量和奇异值子块;$H^{c,m}$ 是通道 $c$ 在频带 $m$ 上的表示。论文默认 $M=3$,每个通道维度 64,因此可以按 22/21/21 的规模切分奇异方向。对节点 $n$,三通道的第 $m$ 个频带拼接为:
接下来是 task-aware band gate 和 band weight:
符号解释:$\alpha_n^m$ 是节点相关的频带门控,$\rho$ 控制门控扰动强度,$\phi_m(\cdot)$ 是门控函数,$\omega_m$ 是全局频带权重,$e_n$ 是融合后的节点 embedding。这里的直觉是,低频带提供跨模态共享结构,高频带保留局部差异,门控决定某个用户或 item 在不同频带上应该放大多少。BRIDGE 没有把高频单独拿去全局打分,而是把频率结构保留在 backbone 内,让候选集合本身更稳。
这个设计还有一个容易被忽略的细节:论文比较了 SVD 分解、Gram 固定基、DCT 固定基、随机正交基和无分解等控制。结果显示重要因素不完全是某一个特定基,而是保留稳定的 band split 并配合频率正则。换句话说,DFGE 不是“因为 SVD 魔法所以有效”,而是通过频带结构把共享语义和局部排序变化分开,再让后续 CRI 只在候选内消费这些变化。
2.3 BEN:从训练期共用户行为到有符号证据
BEN 的任务是把训练期共用户 overlap 转成用户-候选对上的行为支持。先固定训练交互集合 $D_{\mathrm{tr}}$,只用训练 split 构建 item-item 行为图。对 item $i$ 和 item $j$,原始行为边定义为:
符号解释:$U_i^{\mathrm{tr}}$ 是训练集中与 item $i$ 交互过的用户集合,$B_{ij}$ 是余弦式共用户相似度。这个式子只看训练交互,避免把验证或测试行为泄漏到行为图里。对用户 $u$ 和候选 item $i$,BEN 会把用户历史中的 item 与候选之间的行为边聚合起来:
符号解释:$H_u^{\mathrm{tr}}$ 是用户 $u$ 的训练历史,$\tilde b_{ui}$ 是候选 $i$ 与用户历史的归一化共用户支持。为了让它可以变成有符号 residual,论文再做 user-wise normalization:
符号解释:$\mu_u$ 和 $\sigma_u$ 是用户 $u$ 的行为证据均值与标准差,$\epsilon$ 防止分母为零。虽然 $B_{ij}$ 和 $\tilde b_{ui}$ 都非负,归一化后的 $b_{ui}$ 可以是正也可以是负。正值表示该候选相对用户历史有强于平均水平的行为支持,负值则表示低于用户平均行为支持。这个有符号性让 BEN 不只是 boost 机制,也可以在候选内部 demote 看似相关但行为证据不足的 item。
BEN 和普通 ItemKNN 的差别在于使用位置和归一化口径。普通 ItemKNN 可以直接当召回或 reranking 特征,容易把热门项和历史共现强项整体抬高;BEN 则把共用户相似转成用户内标准化证据,再交给 CRI 的候选 mask。这样行为信号不会独立决定全局排名,而是在 backbone 已经授权的 shortlist 里提供局部方向。论文还说明,当完整用户-物品行为矩阵能放进内存时,可以预先归一化每个用户的完整行为行;在更大稀疏数据上,也可以按需计算,二者保持同一公式,避免训练和推理口径不一致。
2.4 CRI:候选残差积分器
CRI 是论文最像工程模块的部分。它先由 base score 给每个用户选出候选集合,再只在该集合里应用 BEN residual。主版本使用验证集选择的固定残差强度:
符号解释:$C_u^{\mathrm{tr}}$ 是训练阶段由 detached base score 选出的候选集合,$\mathbb{I}[\cdot]$ 是候选内指示函数,$\lambda_b$ 是验证集选择的残差强度,$b_{ui}$ 是 BEN 输出的行为证据。论文也提供一个更保守的可学习系数控制:
符号解释:$\beta_u$ 和 $\beta_i$ 是用户与 item bias,$a_s$、$a_b$ 是标量系数,$\eta_{ui}$ 是位于 0 到 1 的保守 gating。主实验最终选中的通常是固定 $\lambda_b$ 的候选校准,而不是更复杂的 gating。这一点很有启发:论文并不是靠更大的校准网络获得收益,而是靠候选作用域和归一化行为证据获得收益。
候选集合本身也有明确训练口径。训练时先用 stop-gradient 的 base score 形成候选:
符号解释:$\operatorname{sg}(\cdot)$ 表示 stop-gradient,$K_c$ 是候选大小。候选集合只作为 scope mask,不作为额外监督目标。训练打分为:
推理时使用同样的候选范围逻辑:
符号解释:$C_u$ 是推理阶段 base score 的 top-$K_c$ 候选集合。论文报告的设置使用 $K_c=200$,$\lambda_b$ 从 0.1、0.2、0.4、0.6、0.8 的小网格中按验证 Recall@20 选择。候选 mask 的意义是训练和推理 scope 一致。如果训练时让 residual 对全局采样 item 生效,推理时却只在 top-$K$ 内应用,就会出现 scope mismatch。BRIDGE 通过 detached candidate set 让 residual 从训练开始就只学习候选内校准,候选外 item 仍靠 base loss 学习进入未来候选。
2.5 训练目标和正则项
BRIDGE 的主排序损失是校准后的 BPR:
同时保留基础分数上的辅助 BPR:
符号解释:$L_{\mathrm{rank}}$ 训练候选内校准后的分数,$L_{\mathrm{base}}$ 保证 backbone 本身仍然有预测能力。这个辅助项很重要,因为如果某个正例暂时没进候选集合,残差分支不会激活,只有 base loss 能推动它以后进入候选。
频带门控还有 information bottleneck surrogate。令 $\gamma_{n,m}$ 是节点 $n$ 在频带 $m$ 上的 gate,$\delta_{n,m}=\max(\gamma_{n,m}-1,0)$,则:
符号解释:$N$ 包含编码器用到的用户和 item 节点,$\boldsymbol{\delta}_n$ 是节点 $n$ 的频带扩张向量,$\phi^+$ 是允许的正向扩张阈值。这个项鼓励 gate 不要无节制放大某个频带,若节点无需强放大即可表达,就让 gate 靠近 1。
频率结构正则由 decorrelation 和 high-frequency discrimination 两部分组成:
其中 decorrelation 抑制不同频带冗余,discrimination 保持高频带的排序能力。论文给出的形式可以理解为:对一个训练 batch $B=\{(u_b,i_b,j_b)\}_{b=1}^{B}$,用归一化频带向量 $\tilde h=h/(\|h\|_2+\epsilon)$,让同一用户或 item 的不同频带不要彼此过度相似,同时让高频带在正样本对之间保留可判别信号。最终目标是:
符号解释:主固定 $\lambda_b$ 版本中,$\lambda_{\mathrm{base}}=0.2$、$\lambda_{\mathrm{IB}}=1.0$、$\lambda_{\mathrm{freq}}=0.001$、$\lambda_{\eta}=0$;保守系数控制版本才启用 $L_{\eta}$。这个目标函数把论文的设计意图写得很直接:DFGE 必须保持候选几何和频带结构,BEN 必须提供训练期行为证据,CRI 必须只在候选内让该证据改变分数。
3. 实验结果
3.1 实验设置和可比性
论文使用 Amazon Baby、Sports、Electronics 三个多模态推荐数据集,沿用 MMRec 风格的 implicit-feedback split,并统一使用 BEIT3-derived multimodal features。Baby 包含 19,445 个用户、7,050 个 item、160,792 条交互;Sports 包含 35,598 个用户、18,357 个 item、296,337 条交互;Electronics 包含 192,403 个用户、63,001 个 item、1,689,188 条交互。评估使用 full-sort protocol,指标是 Recall@10、Recall@20、NDCG@10 和 NDCG@20。论文明确强调行为图只从 training split 构建,validation 和 test 交互不进入 BEN;Baby 的训练、验证、测试交互数分别是 118,551、20,559、21,682,Sports 是 218,409、37,899、40,029,Electronics 是 1,254,441、211,296、223,451。
基线覆盖传统协同过滤、多模态图推荐和近期强多模态模型,包括 BPR、LightGCN、VBPR、MMGCN、GRCN、DualGNN、SLMRec、LATTICE、BM3、FREEDOM、DiffMM、MMIL、AlignRec、SMORE、FITMM。这个基线组合比较完整:BPR 和 LightGCN 检查纯协同过滤能力,VBPR 和图多模态方法检查内容特征是否有效,AlignRec、SMORE、FITMM 等强基线检查 BRIDGE 是否只是吃到旧模型没对齐的红利。强基线和 BRIDGE 报告 5 个随机种子的均值和标准差,并用独立两样本 $t$-test 标注显著性;其余基线作为统一协议下的单 run 控制。多模态推荐结果很容易被 split、feature cache、full-sort/采样评估差异影响,因此这些协议说明比单个数字更重要。
3.2 主结果:BRIDGE 更像 top-rank sharpening
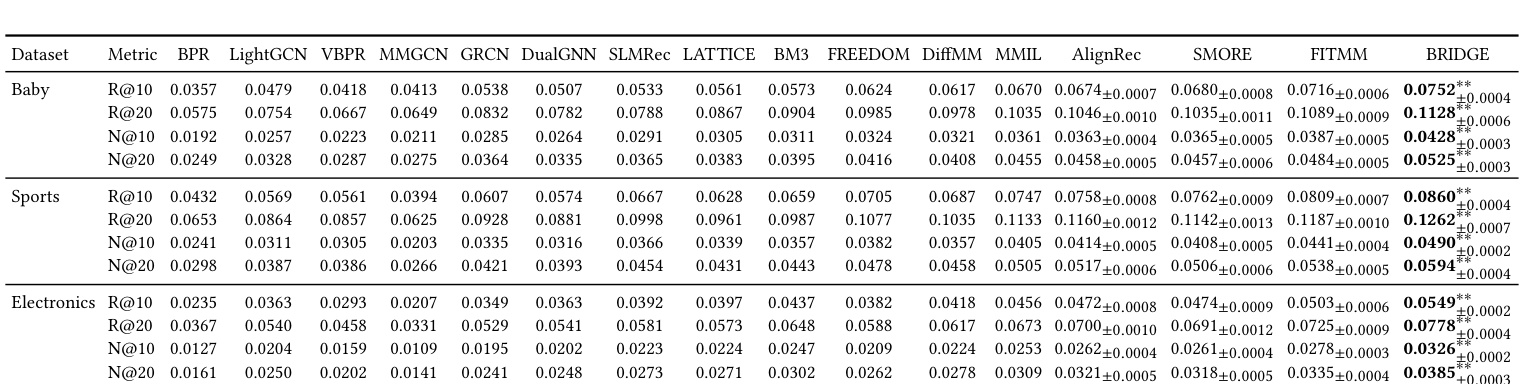
Table 1 是主结果。BRIDGE 在 Baby、Sports、Electronics 上的 Recall@20 分别达到 0.1128、0.1262、0.0778,对应 NDCG@20 为 0.0525、0.0594、0.0385,所有数据集和所有指标均优于表中基线。和最强基线 FITMM 相比,Baby 的 Recall@20 从 0.1089 提到 0.1128,NDCG@20 从 0.0484 提到 0.0525;Sports 的 Recall@20 从 0.1187 提到 0.1262,NDCG@20 从 0.0538 提到 0.0594;Electronics 的 Recall@20 从 0.0725 提到 0.0778,NDCG@20 从 0.0335 提到 0.0385。可以看到 NDCG 的相对收益普遍更突出,这与方法目标一致:BRIDGE 没有试图让行为残差重写全目录,而是在 base backbone 形成的 shortlist 内更精细地移动正样本位置。Recall 提升说明候选内部覆盖有改善,NDCG 提升说明靠前位置的排序更准,后者才是候选校准最直接的收益信号。
按数据集看,Baby 的绝对提升较小但稳定,Sports 的 Recall 和 NDCG 都有比较均衡的提升,Electronics 的 NDCG 收益尤其明显。论文解释这和稀疏性和 popularity skew 有关:在更稀疏、更长尾的 Electronics 上,全局残差更容易误导排序,而候选受限 residual 更能发挥局部校准作用。这个观察对工业场景有参考价值。很多线上多模态特征在冷启动和长尾内容上看似有效,但若没有候选边界,最终可能只是把热门模板和内容相似项推高。BRIDGE 的结果说明,把行为证据局限在 backbone 已经认为可行的候选里,可能更适合处理稀疏区域的排序细节。
3.3 机制控制:收益来自候选限制和行为证据的组合
论文的 ablation 不是只做“去掉一个模块看下降”,而是围绕三个问题组织:BEN 和 CRI 是否真的需要行为证据与候选限制;DFGE 是否真的需要频带结构;残差收益是否只是 popularity amplification。Table 2 的 Baby ablation 显示,完整 BRIDGE 的 R@20 为 0.1128,去掉 behavior evidence 降到 0.1016,去掉 top-$K$ calibration 为 0.1025。也就是说,只有行为证据但没有正确 scope,或者只有候选体系但没有行为证据,都不能保留完整收益。global correction 虽然能恢复一部分,但仍低于候选受限的 BRIDGE,因为它允许 residual 触达 base encoder 没有授权的 item。
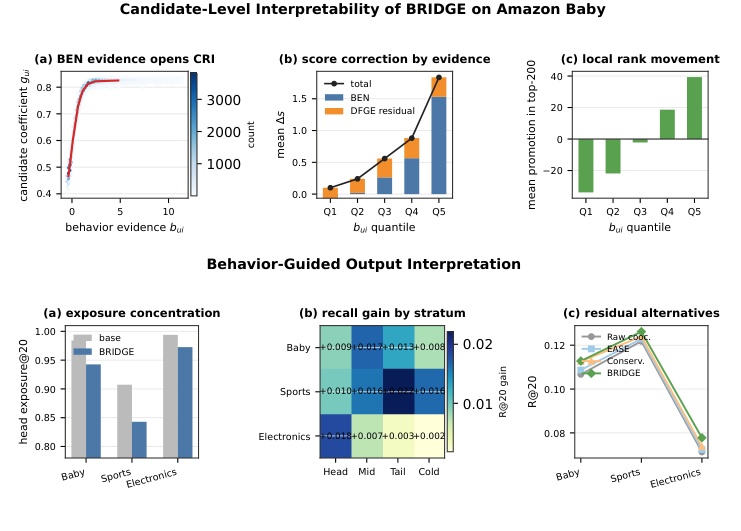
Figure 3 把这种机制解释得更直观。上排左图显示 BEN evidence 上升时 candidate coefficient 快速打开,说明行为证据确实在控制 CRI 是否工作;上排中图把 score correction 拆成 BEN 和 DFGE residual,证据分位越高,总修正越大;上排右图显示低证据分位的候选会被降位,高证据分位的候选会被提升。下排则从输出侧验证是否只是推热门:head exposure 在 BRIDGE 下下降,分层 recall gain 覆盖 Head、Mid、Tail、Cold,residual alternatives 中 Raw cooc. 和 EASE 都不如 BRIDGE 稳。最关键的是,这张图说明 BRIDGE 的 residual 不是“所有行为相似 item 都加分”,而是把候选内部的位置向更有行为支持的 item 重新分配。若一个系统担心多模态模型放大头部曝光,这种分层诊断比单看整体 Recall 更有解释力。
Table 2 的 residual alternatives 也很值得看。Baby 上 Raw cooc. 的 R@20 为 0.1067,EASE 为 0.1087,保守系数版本为 0.1126,完整 BRIDGE 为 0.1128;Sports 上 BRIDGE 为 0.1262,高于 Raw cooc. 的 0.1218、EASE 的 0.1229 和 conserv. coeff. 的 0.1240;Electronics 上 BRIDGE 为 0.0778,高于 0.0713、0.0724 和 0.0738。这个排序说明 BEN 不是普通共现邻域,CRI 也不是可以随便换成一个更强 residual head 的位置。共现有用,但必须先做用户内归一化,并受候选边界限制。
DFGE 的控制实验说明 item graph 和多模态内容仍然是基础。去掉 item graph 的下降很明显,去掉图像或文本单模态也会下降,说明视觉和文本是互补而不是完全替代。频率侧,去掉 IB surrogate 或 frequency regularizer 会损害性能,但 Gram、DCT、随机正交基和 SVD 的差距相对有限。我的理解是,论文真正证明的是“需要频带结构和结构正则”,而不是“必须用某一个神奇 SVD 基”。这对复现者比较友好:若系统无法承受完整 SVD 管线,可以先复刻候选 residual 和频带分解控制,再评估是否需要更重的 decomposition。
3.4 流行度分层和复现口径
Table 4 从 Head、Mid、Tail、Cold 分层看结果。Baby 上 base R@20 为 0.1017,BRIDGE 固定 $\lambda$ 后为 0.1128,Head、Mid、Tail、Cold 分层 recall 分别是 0.1739、0.0261、0.0189、0.0109,head exposure 从 base 的 0.9842 降到 0.9426。Sports 上 base R@20 为 0.1141,BRIDGE 为 0.1262,head exposure 从 0.9073 降到 0.8429;Electronics 上 base 为 0.0637,BRIDGE 为 0.0778,head exposure 从 0.9939 降到 0.9726。这个结果说明 BRIDGE 不是用反热门正则硬压头部,而是在候选内把部分排序质量转移给有行为和内容共同支持的中长尾 item。
复现时最容易踩坑的不是公式,而是评估口径。论文主设置使用 64 维 embedding、2 层图传播、3 个频带、item graph 10 个邻居、学习率 $10^{-4}$、正则权重 $10^{-3}$、IB 权重 1.0、behavior top-$K$ 1000、behavior evaluation top-$K$ 200、train candidate top-$K$ 200、Adam 训练 300 epochs,batch size 2048 或 4096,seed 2020。行为图使用 cosine similarity、sum-sqrt aggregation 和 z-score normalization。若只实现模型结构但换了 feature cache、候选 size、full-sort evaluator 或验证选择口径,很容易把 residual 的作用范围改掉,导致结果不可比。建议复现时先做四个最小对照:base encoder、global residual、candidate residual without BEN normalization、完整 BRIDGE。只有候选 residual 在 NDCG 和流行度分层上同时更好,才说明真正复现到论文的机制。
4. 总结
4.1 我的判断
BRIDGE 的价值不在于给多模态推荐又加了一个缩写,而在于明确提出“内容证据的排序权限需要被约束”。它承认视觉和文本能改善候选几何,也承认行为共现能帮助候选内排序,但不允许任何一种证据全局自由改写分数。这个设计比单纯堆 encoder 更接近真实推荐链路:召回和粗排给出候选边界,精排或重排在边界内使用更细信号。论文用频谱诊断说明为什么强跨模态一致性会压掉推荐差异,用 BEN/CRI 说明行为证据如何变成有符号局部 residual,再用主结果、消融和流行度分层证明收益不是简单热门放大。
我认为最值得迁移的是候选受限校准,而不是某一个具体公式。今天很多推荐系统会引入 LLM 商品标签、视觉 embedding、文本 embedding、知识图谱、用户长期兴趣摘要或广告语义属性。新语义信号很强,但越强越需要作用域。如果把它直接接到全局分数上,模型可能获得短期 Recall,却破坏稳定排序和曝光结构。BRIDGE 给出的范式是:新语义信号先进入 backbone 或候选生成,再由真实行为证据授权它是否能在候选内部调整最终分数。
4.2 工程启发
工程落地可以从一个比论文更小的版本开始。第一步保留现有召回或粗排 backbone,不急着替换成完整 DFGE;第二步只用训练日志构造 item-item 共用户支持,并按用户做标准化,保证 residual 有正有负;第三步在 base top-$K$ 候选内应用小网格选择的 $\lambda_b$,对比全局 residual、候选 residual、无 residual 和原始 ItemKNN;第四步同时看 NDCG、Recall、head exposure、mid/tail/cold 分层,以及不同用户活跃度上的收益。若候选 residual 已经稳定改善,再考虑加入频带分解、IB surrogate 和 frequency regularizer。
上线前还要检查三个风险。第一,BEN 来自训练期共用户行为,如果日志有强曝光偏差、机器人行为或活动流量,residual 会把这些偏差标准化后带入候选内排序。第二,候选受限既是优点也是天花板,base top-$K$ 没有召回的 item 不可能被 CRI 恢复,所以 backbone 质量仍然是上限。第三,$\lambda_b$ 虽然是小网格,但不同业务目标可能有不同最优点,NDCG、GMV、观看时长、复购和多样性未必同时最优。论文的固定 $\lambda_b$ 是一个可解释起点,不应被理解成所有场景都足够。
4.3 局限和后续跟进
论文的局限主要有四点。第一,实验集中在 Amazon review 多模态推荐,虽然口径清晰,但与实时内容流、电商广告、短视频和搜索推荐仍有差距。第二,行为证据是训练期 co-user overlap,这类信号天然受历史曝光和用户群体结构影响,未必能处理兴趣突变和短周期热点。第三,DFGE 的频率解释是 representation-spectral ordering,不是严格图拉普拉斯频域,读者不能把它等同于所有图信号处理意义上的低频/高频。第四,候选内校准无法修复候选生成失败,若 base scorer 没有把正例放进 top-$K_c$,残差模块没有权限恢复。
后续我会重点看三个方向。第一,检查开源实现里候选集合是否按论文所说由 detached base score 动态重算,以及训练和推理的候选 size 是否一致。第二,把 BRIDGE 的候选 residual 思路和 LLM 生成属性、商品图谱属性、用户长期兴趣摘要结合,观察新语义信号是否能在不放大热门曝光的情况下改善 NDCG。第三,在真实多阶段链路里把它作为重排层校准模块,而不是替换召回或粗排模型,这样更符合论文“base candidate geometry plus local residual”的设计边界。