DeferMem:DeferMem: Query-Time Evidence Distillation via Reinforcement Learning for Long-Term Memory QA
这里精读一篇 2026-05-21 公开在 arXiv 的论文《DeferMem: Query-Time Evidence Distillation via Reinforcement Learning for Long-Term Memory QA》。中文可以叫《通过强化学习在查询时蒸馏证据的长期记忆问答》。论文链接:arXiv:2605.22411。作者为 Jianing Yin、Tan Tang,机构/团队为 State Key Lab of CAD&CG, Zhejiang University。代码/项目页本轮未核验到独立仓库。本地 PDF 为 多校-DeferMem.pdf。
DeferMem 关注长期记忆系统的一个核心错位:很多系统在未来查询还没出现时就压缩、总结或重组历史,但真正回答问题时需要的证据往往依赖具体 query。论文因此把证据蒸馏推迟到查询时,先高召回取候选,再用 DistillPO 训练的 distiller 生成自包含证据。
1. 背景和问题
LLM agent 的长期记忆需要保存跨会话历史、用户偏好、事实状态和过去对话中的细节。随着上下文窗口变长,直接把所有历史塞进 prompt 仍然不可行:注意力会被大量无关内容稀释,关键信息可能落在中间位置而被忽略,token 成本和延迟也会随历史增长。外部记忆系统因此成为长期交互 agent 的基础模块。
现有记忆方案通常在 query 到来前就整理历史,例如生成摘要、构建图、压缩消息、维护结构化 memory unit 或做 forgetting/update。这些机制有利于存储和检索,但它们必须在不知道未来问题的情况下决定什么重要。问题是,某条细节当下看起来不重要,未来某个 query 却可能正好需要它;预先压缩如果删掉实体、时间、约束或上下文,后续 retrieval 再强也找不回原始证据。即使保留原文,常见 embedding similarity 或 keyword matching 也只能给出粗候选,不能保证候选是 answer-useful evidence。
1.2 预组织记忆与查询时证据需求的错位

Figure 1(原文图 1)对比了既有 memory systems 和 DeferMem。左侧流程在 future query 未知时就做 pre-organized memory,然后在 query 到来后通过 similarity-based retrieval 找候选;右侧 DeferMem 保留 raw history 和 high-recall segment-link structure,在 query 已知后才做 query-conditioned evidence distillation。图中的关键差别是时间点:传统流程过早决定什么信息值得保留,DeferMem 则先避免过度压缩,再让具体问题决定哪些候选需要被选择和改写成证据。这个设计特别适合长期 QA,因为答案证据常常分散在多轮、多会话、多事件中,不能只靠预先摘要决定。
2. 方法
2.1 Segment-link retrieval 与 query-conditioned evidence distillation
DeferMem 的总体流程分为两阶段。第一阶段是 segment-link retriever:把原始对话历史切成 segment,并通过 lightweight link structure 组织相邻、相关或可扩展的消息块,查询到来时产生高召回候选。第二阶段是 memory distiller:在候选里选择必要消息,并把它们改写成 faithful、self-contained、query-conditioned evidence,供下游 answerer 使用。这个分工明确:retriever 容忍噪声但要覆盖,distiller 负责把噪声变成可回答证据。
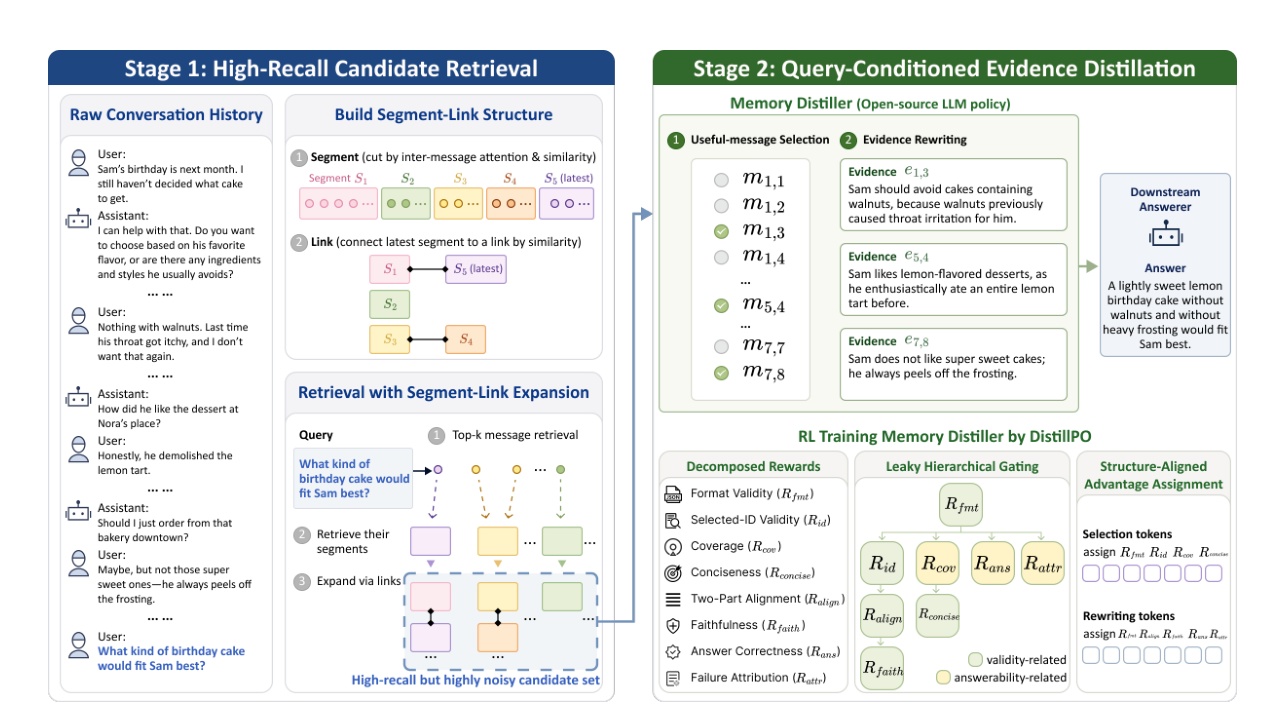
Figure 2(原文图 2)左侧是 Stage 1 High-Recall Candidate Retrieval,包括 raw conversation history、segment-link structure、query 和 segment-link expansion;右侧是 Stage 2 Query-Conditioned Evidence Distillation,包括 memory distiller、selected messages、rewritten evidence、distilled memories 和 downstream answerer。图底部还展示训练 memory distiller by DistillPO:decomposed rewards、lazy hierarchical gating、structure-aligned advantage assignment 等模块共同约束输出。读这张图时要注意,高召回候选不是最终上下文,候选里可以有大量噪声;真正影响答案的是 distiller 选择哪些消息、如何改写、是否保持证据忠实和自包含。
2.2 DistillPO:把证据蒸馏写成结构化动作
DistillPO 将 post-retrieval evidence distillation 定义为结构化动作:一部分动作选择消息,一部分动作改写证据。奖励也不是单一分数,而是 decomposed-and-gated reward pipeline:先检查 JSON/schema 或格式合法性,再检查选择质量、证据忠实性、查询相关性和答案可用性。Gating 的意义是避免后面的质量 reward 在前置结构无效时误导模型。
Structure-aligned advantage assignment 则让不同 reward 对应到负责的输出 span。比如消息选择错误应主要影响 selection 部分,证据改写幻觉应主要影响 rewriting 部分。这样的 credit assignment 比把整段输出打一个总分更细,适合长期记忆这种多步骤任务。它也说明 DeferMem 不只是一个 retrieval heuristic,而是把 evidence distillation 作为可训练组件来优化。
2.3 与 RAG 和摘要式记忆的差别
普通 RAG 往往把检索候选直接交给下游模型,依赖 answerer 自己在 prompt 里筛选;摘要式记忆则提前压缩历史,减少 token 但可能损失细节。DeferMem 介于两者之间:不在写入时过早压缩,也不把大批候选直接塞给 answerer,而是在 query-time 通过 distiller 产生小而准的证据集合。这对 agent 长期记忆有实际意义,因为记忆操作成本、证据质量和答案准确率可以被分开优化。
3. 实验结果
3.1 设置与基线
实验在 LongMemEval-S 和 LoCoMo 上评估长期记忆 QA。基线包括 FullText、NaiveRAG、Mem0、A-Mem、MemoryOS、MemGAS、LightMem、GAM、Memory-R1 等。指标包括 QA accuracy、token cost 和 time cost。这样的设置既看答案准确率,也看 memory operation 成本,符合长期记忆系统的核心 trade-off:不能为了准确率把所有历史都交给下游模型。
3.2 主结果:准确率和成本 frontier
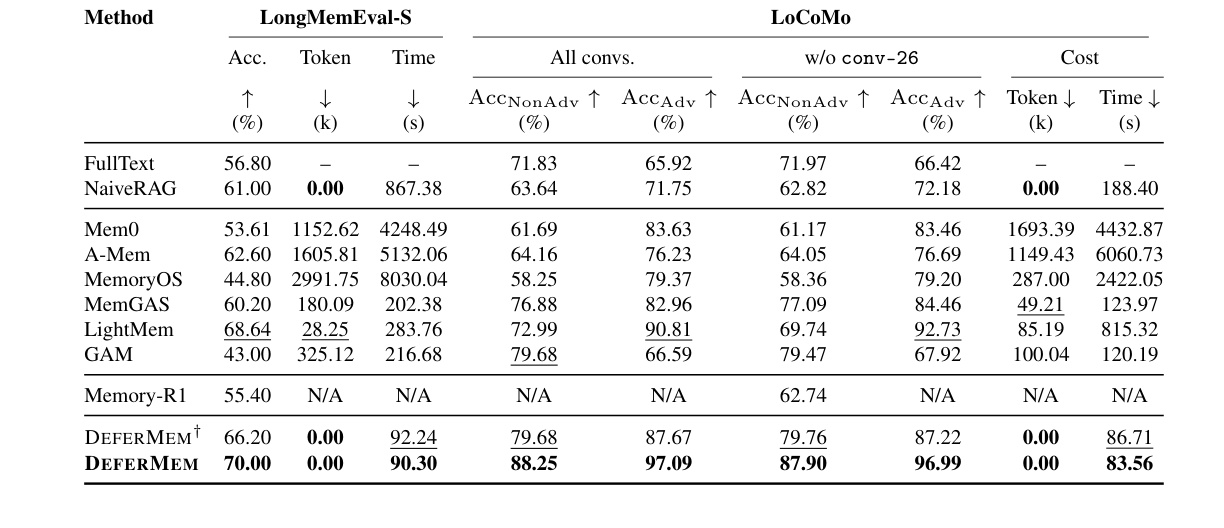
Table 1(原文表 1)比较 LongMemEval-S 和 LoCoMo 上的 accuracy、token cost 与 time cost。DeferMem 在两个数据集上都取得很强的 QA accuracy,同时 memory-operation token cost 为 0,因为它不依赖商业 API 做记忆操作;time cost 也较低。表中一个重要对比是 FullText 或强 RAG 类方法可能保留更多原始信息,但会带来显著 token 和时间开销;而一些压缩型记忆虽然便宜,却可能在需要细粒度证据时丢失信息。DeferMem 的结果说明 query-time distillation 可以把高召回候选压成答案可用证据,从而改善准确率与成本的 frontier。
3.3 消融与可扩展性
论文的 Table 3 消融显示,绕过 distiller、直接把 segment-link candidates 喂给 answerer 会明显降低准确率;用 segment-level 或 message-level RAG 替代 segment-link expansion 也会损失效果。对 distiller 而言,base model、SFT、vanilla DAPO 都不如 DistillPO,移除 reward pipeline 或 structure-aligned advantage assignment 也会带来下降。这些结果支撑一个判断:高召回 retrieval 只是第一步,关键是训练一个能选择并改写证据的 query-conditioned distiller。
可扩展性方面,论文还讨论 LongMemEval-M 和错误类型。DeferMem 在更长历史上保持相对可接受的性能变化,retrieval miss 不是主要失败来源,更多错误来自 distillation 或 answerer 使用证据的阶段。这对工程排错有价值:如果 retrieval 已经高召回,就不应盲目扩大候选,而应检查证据选择、改写忠实性和 downstream answerer 的证据利用。
3.4 表格之外的错误归因
DeferMem 的主表说明 accuracy 和成本 frontier 改善,但更重要的是后续错误归因。论文指出 retrieval miss 相对少见,说明 segment-link retriever 大体能覆盖必要候选;主要风险转移到 distillation 和 answerer 阶段。这个结论对工程排障很有用。如果线上长期记忆问答失败,第一反应不应该总是扩大检索 K 或塞更多历史,而要检查 distiller 是否选择了错误消息、是否把证据改写得过度概括、是否丢掉时间顺序和实体约束,以及 answerer 是否正确使用 distilled evidence。过度扩大候选会增加噪声和延迟,未必解决根因。
4. 总结
4.1 我的判断
DeferMem 的核心贡献是把长期记忆的“写入时压缩”改成“查询时证据蒸馏”。这个改变看似简单,但对 agent 记忆很关键。用户长期历史里哪些信息重要,往往要等问题出现才知道;提前摘要容易损失细节,直接检索又容易把噪声交给 answerer。DeferMem 用高召回检索加训练型 distiller,在这两者之间建立了可优化的中间层。
我认为它对个性化 RAG 和推荐用户画像也有启发。用户画像不应只在离线固定压缩成几个标签,而应在具体推荐请求或问答场景下重新蒸馏证据。例如同一段购买历史,对“帮我找耐用的通勤包”和“我上次为什么退货”需要不同证据。DeferMem 的思路可以迁移为 query-conditioned profile distillation。
4.2 工程启发与复现建议
最小复现可以先实现 segment-link retriever,不必一开始训练完整 DistillPO。先把对话切成 segment,构建 message-level 和 segment-level link,保证 candidate recall;再用一个指令模型做 evidence selection and rewriting,人工或弱监督评估 evidence fidelity;最后再引入 RL reward。评估时必须分开记录 retrieval recall、distillation precision、answer accuracy、token cost 和 latency,不能只看最终 QA accuracy。
上线长期记忆系统时,还要保存原始历史,避免 distiller 输出成为唯一证据。Distilled evidence 适合进入 answer prompt,但审计、纠错和用户隐私删除仍需要回到原始消息。对隐私敏感场景,query-time distillation 还要检查是否把无关隐私字段带进证据。
4.3 局限与后续跟进
局限方面,第一,DistillPO 训练需要 reward 设计和结构化输出约束,工程实现复杂度高于普通 RAG。第二,若原始历史本身缺失或 segment-link recall 不足,distiller 无法恢复不存在的证据。第三,证据改写可能引入 paraphrase 幻觉,即使答案正确也可能改变细节含义。第四,论文未核验到独立代码仓库,reward pipeline、gating 阈值和训练数据构造仍需等待实现确认。
后续跟进应关注三点:一是作者是否发布 DistillPO 训练代码和 reward 组件细节;二是 DeferMem 在更开放的多轮 agent、个性化助手和推荐问答中是否仍然优于强 RAG;三是如何为 distilled evidence 增加可追溯引用,让每条改写证据都能回到原始消息,便于审计和纠错。
4.4 和推荐用户画像的关系
长期记忆和推荐用户画像有相似结构。传统画像常在离线阶段把用户历史压成兴趣标签、长期偏好或 embedding,但具体推荐请求到来时,真正有用的证据取决于上下文。例如用户问“适合今天通勤的鞋”和“适合周末徒步的鞋”,需要从相同购买历史中蒸馏不同证据。DeferMem 的 query-time distillation 思路可以迁移成 request-conditioned user evidence:保留原始行为和会话结构,在请求到来后抽取与当前目标相关的历史片段,再交给排序或解释模块。这样比固定画像更灵活,也更容易解释推荐依据。