LLM Ad Retrieval:LLM Retrieval for Stable and Predictable Ad Recommendations
这篇 arXiv:2605.21969 论文来自 Meta Platforms, Inc.,公开版本标注为 SIGIR 2026 AgentSearch Workshop。它讨论的不是“怎样用 LLM 做一个更像文本匹配的召回器”这么简单,而是在广告候选生成阶段引入 LLM 语义表征后,如何让系统在广告素材轻微扰动时仍然保持稳定、可解释、可预测。论文未核验到独立代码仓库或项目页;阅读重点应放在 A/A′ 影子广告评估框架、LLM 语义属性抽取、图遍历扩展和在线 A/B 指标之间的对应关系。
1. 背景和问题
广告推荐系统长期以点击、转化、召回率、NDCG、normalized entropy 这类“预测准确性”指标为中心。这样的指标适合回答一个经典问题:给定用户、场景和候选广告,模型是否把更可能产生点击或转化的广告排在前面。但在大规模广告系统里,另一个更偏工程和商业可信度的问题同样重要:如果广告主只改了很小一处素材、标题、描述、创意或某个非语义字段,系统输出是否会出现不成比例的波动?如果两个广告在语义上几乎等价,却因为 ad ID、素材细节、冷启动路径或某些稀疏特征差异而得到完全不同的投放表现,那么广告主看到的是不可解释的重复性问题、冷启动问题和探索不足问题。论文把这个问题概括为 prediction stability 和 predictability,并指出随着生成式 AI 降低广告素材生产成本、广告库存和创意变体快速膨胀,这个问题会变得更突出。
传统召回链路通常由多路候选生成组成,例如双塔、embedding、图召回、规则召回或历史行为召回。它们各自可以提高覆盖面,但也容易把语义相近的广告切成很多不稳定的表示:有的路依赖广告 ID,有的路依赖文本 embedding,有的路依赖图邻居,有的路依赖历史转化样本。当新广告或轻微改写广告进入系统时,如果语义等价性不能被候选生成层显式建模,后续排序再强也只能处理已经被召回的候选。也就是说,可预测性问题不是单纯的 ranker calibration 问题,而是从 retrieval 阶段就开始积累的系统问题。
本文的关键视角是:广告主关心的并不只是某个 ad ID 的表现,而是一个语义意图、商品、服务、品牌或创意目标在系统中的一致表达。若广告 A 和影子广告 A′ 只是轻微扰动,系统应该把它们放进相近的语义邻域,让它们在候选生成、曝光、点击、转化等后续环节中有更一致的机会。论文因此引入内部 A/A′ 评估框架:为 primary ad 发布一个带有唯一 ad ID、但只有关键特征轻微扰动的 shadow ad,然后比较 primary/shadow 的归一化转化或曝光差异。这个评估把“稳定性”从抽象抱怨变成可度量的系统指标。
这个问题和广告推荐的商业语境高度相关。自然内容推荐里,创作者通常只看到内容整体表现;广告主则会同时管理 campaign、creative、audience、budget、bid 和多种素材版本。如果系统对近似素材的响应不稳定,广告主很难判断是素材本身变差、预算竞争变化、模型探索不足,还是平台内部召回路径改变。更严重的是,生成式 AI 让广告主可以快速批量生成大量文案和图片变体,原来低频的素材扰动会变成常态。此时系统如果仍然过度依赖非语义 ID 或历史稀疏信号,新素材越多,不可预测的冷启动和欠探索就越多。
已有工作中,语义 ID、embedding 稳定性、图召回和 LLM4Rec 都触及了这个方向,但它们常常分别服务于排序稳定、候选覆盖或语义理解。本文的问题定义更窄也更直接:在广告检索阶段,能否让语义等价或近似等价的广告变体获得更一致的候选扩展机会,并且用在线 A/B 证明这种一致性没有牺牲业务指标。这个定位使它区别于一般的 LLM 推荐综述,也区别于只看离线语义匹配的召回论文。
LLM 在这里承担的角色也值得区分。论文不是让大模型在线生成广告文案,也不是让大模型直接对用户-广告对打分,而是用 fine-tuned LLM 从广告创意和产品描述中抽取层级化语义属性,再把这些属性变成广告之间可遍历的语义图。这样做的目的有两个:第一,把广告从稀疏 ID 和表面文本词形拉回到商品、服务、品牌、场景、上下文类别等语义实体;第二,让候选扩展可以在类别、细分类别、相关类别等层级上运行,从而以可控成本补充语义相近但传统召回未覆盖的广告。这个设计非常工业化:LLM 不在最重的在线排序路径里做长上下文推理,而是在候选生成和 metadata 生产环节提供更稳定的结构化语义。
所以,这篇论文的贡献可以概括为三层。第一,提出并落地 A/A′ predictability 评估,把影子广告差异、统计显著性阈值和收入权重聚合成系统级指标。第二,提出 LLM-based semantic candidate generation,用 LLM 抽取 hierarchical ad semantic attributes,再通过 graph traversal 做 ad-to-ad expansion。第三,在 Meta 的大规模工业广告系统中做在线 A/B,报告 top-line online metric、final-stage recall、A/A′ difference 和 MAD 等指标改善。它的价值不在模型结构复杂,而在把“语义表征是否让系统更可预测”这个问题贯穿到指标、候选生成、服务工程和在线实验中。
2. 方法
2.1 A/A′ 可预测性指标:从单个影子广告对到系统级 guardrail
论文先给出一组评估指标:Recall@K 用于衡量召回集合的相关性,online top-line metric 用于衡量真实广告系统的在线价值,Predictability 或 A/A′ difference 用于衡量轻微广告扰动下投放表现是否稳定,MAD 用于衡量 A/A′ 差异在时间上的波动。这里真正新的是 A/A′ 指标,因为它把“同一个语义意图的轻微变体是否被系统一致对待”转成了可以进实验平台的量化 guardrail。
内部框架会为原始广告 $ad^p$ 构造影子广告 $ad^s$。$ad^s$ 有唯一 ad ID,同时扰动一个关键特征,以模拟广告主对素材或创意做小修改。由于 primary 和 shadow 在语义上应当接近,若系统具备语义意识,它们的 normalized conversion 或 impression 不应出现超出随机波动的巨大差异。论文用 $\Delta$ 表示一对 primary/shadow ads 的转化相对差异,并给出 pair-level StatSigDiff:
符号解释:$ad^p$ 是 primary ad,$ad^s$ 是 shadow ad;$\Delta$ 是这对广告的转化相对差异,论文没有在 PDF 中进一步展开它的归一化细节;$\mathrm{conv}(\cdot)$ 表示广告获得的 optimized conversions 数;$1.65$ 对应高斯近似下约 90% 置信区间的单侧标准差阈值。这个公式的直觉是,样本越少,primary 和 shadow 的差异越可能来自随机噪声,因此可容忍区间更大;样本越多,随机方差越小,同样幅度的差异就更可能表示真实系统偏差。外层 $\max(0,\cdot)$ 表示只有超过统计阈值的差异才被计入惩罚。
这个公式非常适合工业广告系统,因为它没有要求 A/A′ 差异必须为零。真实投放系统有拍卖、预算、竞价、频控、用户在线状态、模型随机性和探索机制,影子广告不可能在每一天、每个桶里完全复制 primary 的轨迹。论文关注的是“显著超出随机噪声的差异”,而不是消灭所有差异。这样,Predictability 就不会和系统探索、实时竞价或业务随机性正面冲突,而是成为开发召回器时的稳定性护栏。
系统级指标再把所有 A/A′ pair 聚合起来:
符号解释:$N$ 是生成的 primary/shadow pair 数量;$ad_i^p$ 和 $ad_i^s$ 是第 $i$ 对广告;$\mathrm{rev}(\cdot)$ 是广告带来的总收入。收入权重使用平方根而不是线性收入,意味着高收入广告更重要,但不会让极少数超大收入广告完全支配指标。这个设计也符合广告平台的工程直觉:高价值广告的不稳定会被广告主更明显感知,但系统级 guardrail 仍然需要覆盖长尾广告。
这套指标的关键不是数学本身,而是它给候选生成提供了可优化方向。传统 recall 或 NDCG 只告诉我们“召回了多少后续排序认为重要的广告”,却不告诉我们“语义等价广告是否获得了相近机会”。A/A′ StatSigDiff 则把召回阶段的语义意识和广告主体验连接起来:如果某个候选生成器依赖 ad ID 或非语义特征,shadow ad 可能因为 ID 改变而落到不同邻域,最终表现差异变大;如果候选生成器基于商品、品牌、场景和上下文语义,primary/shadow 更可能共享邻居和召回机会,指标就会下降。
2.2 LLM 驱动的广告语义表征:把素材转成层级属性
论文提出的 LLM candidate generation 不是端到端替代广告推荐系统,而是嵌入 cascade 多阶段推荐范式的候选生成层。大多数工业广告系统会先用多路召回生成候选,再交给一个或多个重排/精排阶段。候选生成器的核心目标是把尽可能多的潜在相关广告传给后续阶段,同时不超过基础设施容量。本文认为要改善 A/A′ predictability,关键是找到用户与广告的“正确语义表示”,但论文实际范围聚焦在广告侧 candidate generation,而不是完整用户建模。
广告素材包含标题、描述、产品说明、创意文本和上下文信息。传统做法可能把它们转成词袋、文本 embedding、稀疏类别或人工规则标签;本文则使用预训练并在广告数据上 fine-tune 的 LLM,把广告输入转成 retrieval-specific discrete tokens 和层级语义 metadata。论文没有展开 fine-tuning 数据和任务细节,只说明内部已有在 ads engagement datasets 上 fine-tuned 的 LLM,评估中使用 text-only Llama3-8B Instruct 的 zero-shot inference 能力。这一点需要谨慎理解:它展示了 LLM 表征可以生成有效补充 metadata,但并没有提供可复现的训练 recipe 或开源模型。
LLM 表征要满足两个性质。第一是 semantic-aware,即能够识别广告背后的商品、服务、应用、品牌、场景和意图,而不是只看表面词形或 ad ID。例如两条广告文案可能用不同描述卖同类健身服务,传统关键词可能只匹配到部分词,LLM metadata 则更容易把它们归入相近产品和场景。第二是 hierarchical,即可以在粗粒度类别、细分类别、相关类别之间组织计算。层级结构对大规模系统尤其重要,因为它允许先用高层语义缩小搜索,再用更细属性做 relevance scoring,而不是在全量广告上暴力算相似度。
论文把这一点和 graph-based expansion 结合起来:LLM 先抽取广告的层级语义属性,然后广告或类别节点之间通过共享属性建立关系图。候选生成时,系统可以从一个 seed ad 出发,沿着语义图扩展到相近广告。对 A/A′ 来说,这意味着 primary ad 和 shadow ad 即使 ID 不同,也可能被映射到相同或相近的类别、细分类别和相关类别中,从而共享召回邻域。换句话说,LLM 的作用不是神奇地“理解所有广告”,而是把广告投放系统中原本碎片化、非语义化的实体变成可共享、可遍历、可解释的语义结构。
2.3 端到端系统组件:metadata、召回、相关性和服务边界
论文的系统设计包含四个主组件:LLM-driven ads representation learning、scalable infrastructure for LLM processing、semantic navigation / graph traversal algorithms、real-time candidate retrieval and service。它们分别对应“生成语义表示”“规模化处理”“用语义图扩展候选”“把候选服务接入在线系统”。这四个组件共同说明:LLM retrieval 的难点不只是选一个大模型,而是如何把离线语义 metadata 生产、图索引构建、实时候选检索和后续排序容量连接起来。
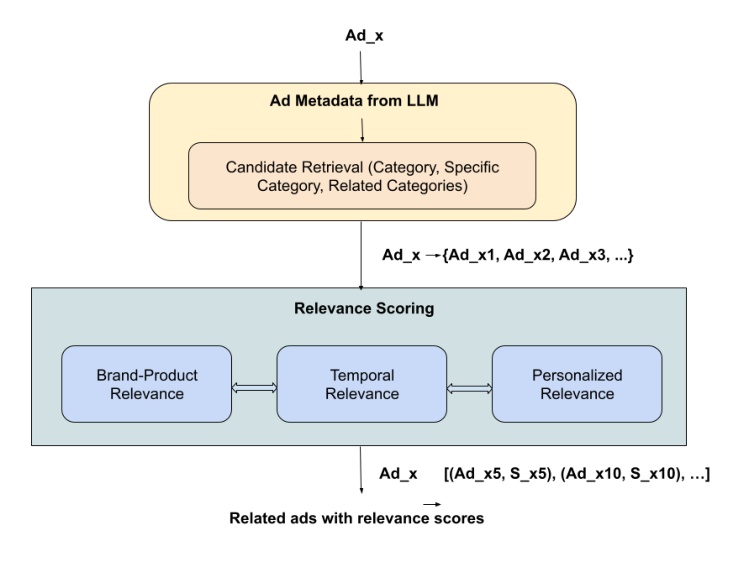
Figure 1 展示了 ad-to-ad generator 的主链路。输入广告 $Ad_x$ 先经过 LLM 生成的 ad metadata,这些 metadata 被用于 candidate retrieval,检索维度包括 Category、Specific Category、Related Categories。然后候选进入 relevance scoring,图中列出 Brand-Product Relevance、Temporal Relevance、Personalized Relevance 三类更深层的相关性维度。输出不是一个简单候选列表,而是若干相关广告及其 relevance scores,例如 $(Ad_{x5},S_{x5})$、$(Ad_{x10},S_{x10})$。这张图的重点在于层级化解耦:LLM 负责把广告语义结构化,第一阶段负责找到大致相关候选,第二阶段再用品牌、商品、时间和个性化上下文做细粒度评分。对工业系统来说,这种拆分比“用 LLM 直接在线打分”更可控,因为最昂贵的语义生成可以批处理,在线路径只消费结构化结果和图索引。
第一个组件是 representation learning。论文描述为将 ad creatives 和 product descriptions 转成 high-dimensional semantic vectors,但随后又强调 LLM 会把世界知识编码为 retrieval-specific discrete tokens,并基于这些 tokens 构建语义图。这里可以理解为“向量表示”和“离散语义属性”并存:向量或 token 用于表达广告语义,离散属性和类别用于图结构与可解释扩展。方法的核心不是追求最强 embedding,而是把细粒度文本和类别 nuance 转成后续候选生成可用的结构。
第二个组件是 scalable infrastructure。论文没有披露具体集群规模,但明确指出需要分布式处理框架满足严格的 latency 和 throughput 需求,并通过高性能 GPU 水平扩展做 batch inference。这里的服务边界很重要:广告系统的在线检索必须低延迟,不能在每次请求时让 LLM 重新阅读广告素材。因此更合理的架构是离线或近线批量生成 ad-level representations 和 metadata,实时服务只查表、走图和计算轻量 relevance score。这也解释了为什么论文强调 horizontal scaling across GPUs,而不是只讨论模型效果。
第三个组件是 semantic navigation。LLM 抽取出的 categories 和 attributes 被组织成 graph,节点可以是广告、类别或相关类别,边表示共享属性或语义关系。系统从 seed ad 出发遍历图,找到 contextually similar ads。这一步承担两个功能:一是扩大候选覆盖,把传统召回未捕获的语义变体补进来;二是提高可预测性,让 primary/shadow 这样轻微不同的广告能够落在相同语义邻域。
2.4 两步相似度:短语优先,token 回退
论文在 4.3 节把 semantic navigation 拆成两个步骤。Step 1 Retrieval 关注为每个候选广告检索大致相关候选,依据是 LLM representations 计算 categorical relevance。Step 2 Relevance Scoring 关注更深维度的 ad-to-ad similarity,例如 brand、product 和 contextual attributes。两步都使用 fuzzy set matching 和 Jaccard similarity,并采取 phrase matches 优先、token matches 回退的策略:
符号解释:$Ad_1$ 和 $Ad_2$ 是两个广告;$P_{Ad_1}$、$P_{Ad_2}$ 是两个广告的 phrase 集合;$T_{Ad_1}$、$T_{Ad_2}$ 是 token 集合;$S(\cdot,\cdot)$ 表示集合相似度,论文语境中为 Jaccard similarity;$\theta$ 是短语级相似度阈值;$S_R$ 是最终 relevance score。短语优先的原因是,广告语义往往以短语为单位出现,例如品牌名、商品名、应用场景或服务组合,单 token 过于碎片化,容易把无关广告误连;但如果短语级匹配不足,token 回退可以保留一定召回能力,避免过度稀疏。
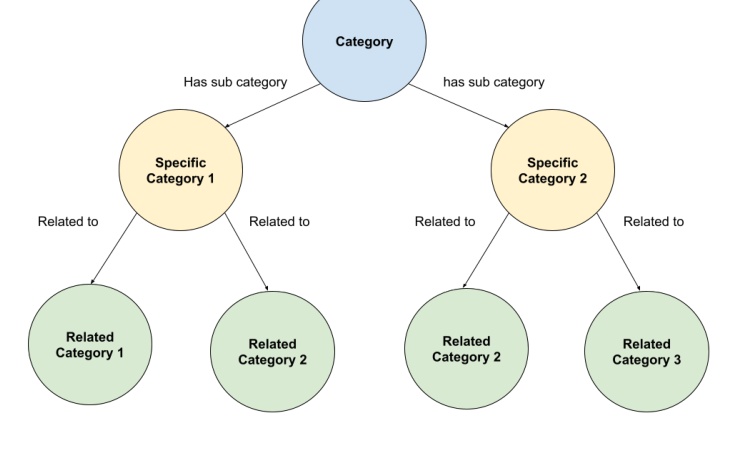
Figure 2 对这个图结构给出简化示意。最上层是 Category,向下连接到 Specific Category 1 和 Specific Category 2;每个细分类别再连接到 Related Category。边上有 “has sub category” 和 “Related to” 关系。这个示意图看起来简单,但它对应广告召回里的一个重要工程选择:系统不必在所有广告之间直接建完全图,而可以通过类别层级间接建立可遍历邻域。若 primary 和 shadow 共享同一 Category 或 Specific Category,即使它们文本表面有小扰动,也能通过同一中间节点扩展到相近广告;若它们在细分类别上不同,但共享相关类别,系统仍能找到语义近邻。这样的层级图也让召回粒度可调:资源紧张时可以只走高置信短路径,资源充裕或需要探索时可以扩展到相关类别。
这个两步相似度还有一个隐含优点:可解释性。若候选广告被召回,不是因为一个黑盒 embedding 距离很近,而是因为它们共享某些 LLM 抽取的 phrase、category、brand-product 属性或 contextual attributes。广告主或内部诊断人员更容易理解“为什么这个广告和另一个广告被视为相似”,这对 predictability 指标也很关键。可预测系统不只是输出稳定,还要能解释稳定来自哪类语义关系。
2.5 两阶段候选生成:类别属性生成与相似广告检索
论文在 4.4 节把 LLM candidate generation 落到两个阶段。Stage 1 是 Categories、Attributes and Contextual Caption Generation,即从广告输入生成类别、属性和上下文 caption。论文给出公式:
符号解释:$f_1$ 是把广告映射到语义类别结果的函数;$Ad$ 是输入广告;$C$ 表示类别空间;$S^{\mathrm{text}}_{Ad}(C)$ 表示广告在文本语义类别空间上的打分结果;$(c_i,s_i)$ 表示第 $i$ 个类别及其分数。这个公式说明 LLM 输出不是单一标签,而是一组带分数的类别。带分数很重要,因为后续检索可以利用类别置信度,而不是把所有标签等价处理。
Stage 2 是 Similar Ads Retrieval,即基于类别交集计算两个广告之间的 retrieval score:
符号解释:$C_{Ad_1}$ 和 $C_{Ad_2}$ 分别是两个广告的类别集合;$c$ 是它们共享的类别;$S_{Ad_1}(c)$ 和 $S_{Ad_2}(c)$ 是两个广告在类别 $c$ 上的得分;$S_R$ 是广告对之间的相似检索分。这个打分形式非常直观:共享类别越多、共享类别上的置信分越高,两个广告越相似。它也能解释为什么层级类别对召回有帮助:如果 LLM 给出的是多粒度类别集合,两个广告可以在不同粒度上产生交集,从而获得更平滑的相似度。
从训练/推理差异看,论文披露的信息有限。训练或 fine-tuning 阶段,Meta 内部已有在广告 engagement 数据上 fine-tuned 的 LLM;评估中使用 text-only Llama3-8B Instruct,通过广告文本描述生成 supplementary metadata。推理或服务阶段,系统将 LLM 生成的 metadata 写入候选生成基础设施,再通过图遍历和 relevance scoring 做 ad-to-ad expansion。也就是说,LLM 推理主要在 metadata 生成阶段,而候选检索本身可以由图索引、集合相似度和轻量打分服务承担。
这条链路的优势在于它与现有广告系统兼容。测试臂只是在 ad retrieval stage 引入 LLM-based candidate generator,其他 delivery flow 保持不变。这使实验更容易归因:如果 top-line metric、recall 和 A/A′ 指标改善,主要来自新增召回路带来的候选变化,而不是整个排序链路同时变化。工程上,这也是最现实的上线方式:先把 LLM 作为增量 candidate generator 接入多路召回,再让 downstream rankers 决定最终排序,而不是直接重构全链路。
2.6 方法边界:这不是通用 LLM4Rec recipe,而是广告召回稳定性方案
需要注意的是,论文并没有解决所有 LLM4Rec 问题。它没有公开训练数据、提示词、fine-tuning objective、metadata schema、类别体系构建细节、图索引更新频率、冷启动广告进入图的延迟,也没有给出线上延迟、GPU 成本或召回路配额。它更像一篇工业系统短论文:给出问题定义、指标、系统框架和在线效果,而不是完整可复现实验。
因此,阅读时不能把它简单归类为“Llama3-8B 做广告召回效果好”。更准确的理解是:当广告系统已经有大规模多路召回和成熟排序时,LLM 可以作为语义 metadata 生产器,把创意文本和产品描述转成层级结构;图遍历和集合相似度再把这些结构变成可服务的候选扩展;A/A′ 指标则确保新增召回路不只是提高点击或转化,还减少轻微素材扰动引发的不稳定。这个闭环才是论文真正的方法贡献。
3. 实验结果
3.1 实验设置:增量召回路而非全链路替换
论文的实验设置相对清晰。模型方面,使用 open-source text-only Llama3-8B Instruct,利用其 zero-shot inference 能力。数据方面,数据集包含约 tens of millions of data points,且只使用 textual descriptions 生成 supplementary metadata。在线实验方面,测试臂在广告 retrieval stage 引入 LLM-based candidate generator,其余 delivery flow 保持不变;baseline 是一个候选生成器 ensemble,包括 two-tower、embedding 和 graph-based generators。这样的对照让新增 LLM 召回路的价值更容易被分离出来。
评估指标分三类。第一类是 canonical ad performance metrics,例如 ad clicks、conversion 和论文中汇报的 top-line online metric。第二类是 retrieval performance,尤其是 final stage recall 和 Top-K candidate quality。第三类是 A/A′ predictability,包括 Equation (2) 定义的 top-line A/A′ difference,以及 daily impression difference 的 MAD。这个指标组合很重要,因为如果一个召回路只提高 top-line metric 却让 A/A′ 更差,它可能带来广告主体验风险;如果只降低 A/A′ 却损害转化,它又难以上线。论文报告的是二者同时改善。
3.2 MAD 与曝光相对差异:时间维度上的稳定性
在 5.2 节,论文进一步定义 daily impression relative difference,用于衡量 primary/shadow 广告对在每天的曝光差异:
符号解释:$(ad^p,ad^s)$ 表示所有 primary/shadow 广告对;$\mathrm{Impression}(ad^p)$ 和 $\mathrm{Impression}(ad^s)$ 分别表示 primary 和 shadow 在某一天获得的曝光量。这个值如果大幅偏离,说明语义近似的广告在投放机会层面有不稳定差异。
随后,论文使用 MAD 衡量这些 daily relative differences 围绕中位数的波动:
符号解释:$day_i$ 是第 $i$ 个测试日;$m$ 是测试期间 impression relative difference 的中位数;$\mathrm{MAD}$ 是每天相对差异相对中位数的 median absolute deviation。MAD 比方差更鲁棒,不容易被单日极端波动支配,适合广告系统这种会受预算、节假日、流量结构和竞价环境影响的在线数据。
这组指标补足了 Equation (1) 和 Equation (2)。StatSigDiff 更强调转化差异是否超过统计噪声,并通过收入权重形成系统级指标;MAD 更强调曝光差异在时间上的稳定性。二者都围绕 A/A′,但观察角度不同:一个偏统计显著的表现差异,一个偏每日投放机会的波动。若 LLM retrieval 真能让语义相近广告共享召回邻域,那么它应当同时降低显著差异和时间波动。
3.3 主效果:在线价值、最终召回和 Top-K 质量
论文报告,在线 A/B 中 LLM candidate generator 在实验 segment 上带来 top-line online metric 统计显著提升 0.45%。从 retrieval performance 看,treatment 使 final stage recall 提升 1.2%。这两个数字幅度不夸张,但在成熟广告系统里并不小,尤其是在“新增一条候选生成路、其他投放链路不变”的设定下,0.45% top-line lift 说明新增候选确实能被下游系统转化为在线价值,而不是只带来低质或冗余候选。

Table 1 给出 Top-K 下的 Recall Alignment Ratio 和 Incremental Recall Potential。Recall Alignment Ratio 从 Top-5 的 0.51X 下降到 Top-200 的 0.07X;论文解释为 LLM candidate generator 在较小 K 值处更集中地对齐 baseline 系统的高质量候选,随着 K 变大,对齐比例下降,说明候选集中包含更多 complement recommendations。Incremental Recall Potential 从 Top-5 的 1.00Y baseline 增长到 Top-200 的 1.89Y,表示在更大候选集合下,LLM 召回路能提供更多传统召回未覆盖的增量潜力。这个表最值得关注的是二者的组合:Top-5 仍有 0.51X 对齐,说明 LLM 不是完全跑偏;Top-200 增量潜力达到 1.89Y,说明它也不是简单复制 baseline。对多路召回系统来说,理想新增路就应该既能命中高质量共识候选,又能提供可被下游排序利用的新候选。
但这个表也有信息缺口。论文没有解释 X 和 Y 的绝对基准,也没有给出 confidence interval、样本拆分、候选路配额、排序前后候选去重方式或不同广告类别下的分层结果。因此,它更适合支持“LLM 召回路有增量价值”的方向性结论,而不适合推导可迁移的绝对收益。实际复现或落地时,需要特别关注新增召回路是否只在某些行业、商品类别、创意丰富广告或高文本质量广告上有效。
3.4 可预测性结果:A/A′ 差异和 MAD 同时改善
系统可预测性是这篇论文最重要的实验点。论文报告,在线 A/B 中 test 相比 control 的 top-line A/A′ difference 相对降低 8.62%,且 Figure 3 显示 daily impression difference 的 MAD 相比 control 改善 45%。这说明新增 LLM 召回路不仅带来更多候选,还让 primary/shadow 广告对的投放差异更小、更平滑。
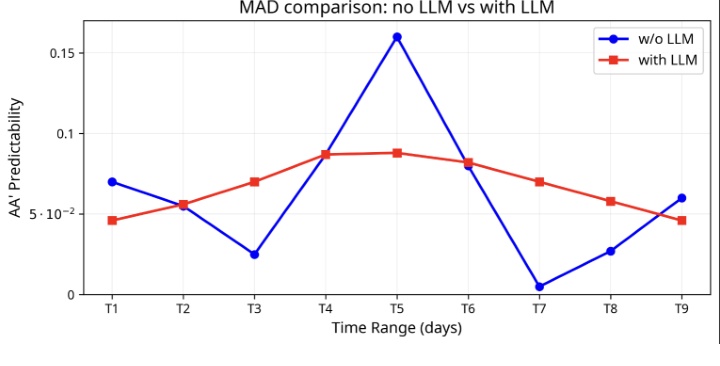
Figure 3 中蓝线是不使用 LLM 的 control,红线是使用 LLM 的 test。蓝线在不同测试日之间波动明显,尤其 T5 附近出现较高峰值,T7 附近又接近低点;红线整体更平滑,虽然也不是完全水平,但峰谷幅度更小。论文据此给出 MAD 改善 45% 的结论。这个图的意义在于,它把“可预测性”从单个汇总数字转成时间序列上的稳定表现:如果 advertiser 对轻微创意改动的投放结果敏感,那么每天波动降低比单日平均值更有业务含义。红线不是证明所有广告都稳定,而是说明 LLM semantic candidate generation 在实验窗口里降低了 shadow/primary 曝光差异的日际振荡。
为什么候选生成层能影响 A/A′?一个合理解释是:传统召回路可能把 primary 和 shadow 看作两个独立实体,它们进入不同候选池或获得不同召回机会;LLM metadata 则把它们投射到共享语义类别和相关类别,因而在 ad-to-ad expansion 中更容易共享邻居。最终,后续 ranker 看到的候选集合更一致,曝光和转化差异就有机会下降。这也说明可预测性不是排序最后一层才能修的问题,召回阶段的语义归一化同样重要。
3.5 结果解读:有效但仍是工业短论文级证据
从结果看,论文给出了一个完整正向链条:LLM semantic metadata 产生候选扩展,final stage recall 提升 1.2%;新增候选被下游系统吸收,top-line online metric 提升 0.45%;primary/shadow 投放差异减少,A/A′ difference 降低 8.62%;日际曝光差异更平滑,MAD 改善 45%。这比单纯汇报离线 Recall@K 更有说服力,因为它覆盖了召回质量、在线业务价值和稳定性三类目标。
不过,它的证据仍然有限。首先,论文没有披露 A/B 时长、流量比例、统计检验细节和不同 segment 的分层结果。其次,Llama3-8B Instruct 的具体使用方式不清楚,是直接 prompt 抽取 metadata,还是配合内部 schema、规则清洗和后处理;这会显著影响可复现性。再次,图遍历和候选数量的成本没有公开,无法判断 0.45% top-line lift 对应的计算和维护成本是否划算。最后,A/A′ 构造依赖内部 shadow ad 框架,不同平台是否能低成本复现这种评估机制,也不是论文能直接回答的问题。
因此,这篇论文更适合作为广告召回系统的设计参考,而不是拿来直接复现某个模型。它提示我们:如果系统有大量广告创意变体、广告主可感知的不稳定问题,以及已经成熟的多路召回和在线实验平台,那么 LLM metadata + semantic graph expansion 是一个值得尝试的增量召回方向;如果系统没有 shadow entity 评估、没有稳定的语义 taxonomy、没有候选路配额管理,那么直接接入 LLM 可能只会增加复杂度,难以证明稳定性收益。
4. 总结
4.1 我的判断
这篇论文的最大价值,是把 LLM4Rec 从“提高推荐准确率”的常规叙事拉到“提高工业广告系统可预测性”的工程叙事里。它没有炫耀复杂模型,而是提出一个很实际的问题:广告主改了小素材,系统为什么会给出不可解释的投放差异?然后用 A/A′ shadow ads、StatSigDiff、收入权重、MAD 和在线 A/B 把这个问题串起来。LLM 在其中是语义结构化工具,不是万能排序器。这种定位很清醒,也更适合大规模广告系统。
4.2 工程启发与复现建议
如果要在真实推荐或广告系统里参考这篇论文,我会优先复现指标而不是模型。第一步先建立 primary/shadow 或近似等价实体评估,确认系统是否真的存在轻微扰动导致的不稳定;第二步设计可解释 metadata schema,把 LLM 输出限制在类别、属性、品牌、商品、场景等可审计字段;第三步把 LLM 召回作为增量路接入,而不是替代现有召回;第四步同时观察 top-line、final recall、A/A′ difference 和 MAD,避免只看某一个指标。对推荐系统而言,这套思路也可迁移到商品改标题、短视频改封面、内容轻微改写、query rewrite 等场景。
4.3 局限和风险
局限主要有四点。第一,论文没有公开 metadata schema、prompt、fine-tuning objective 和后处理规则,可复现性有限。第二,A/A′ 指标依赖内部 shadow ad 机制,外部系统需要额外建设数据生成、预算隔离和实验分析能力。第三,LLM 抽取的语义类别可能引入新偏差,例如把多义商品归错类别、把品牌和品类关系过度连接、对低质量文本广告生成不稳定属性。第四,论文没有给出延迟、GPU 成本、索引更新和候选路配额,因此无法评估收益和成本的边界。
4.4 后续跟进
后续值得跟进三个方向。第一,看 Meta 或其他平台是否继续公开 semantic ID、LLM metadata 和广告可预测性相关工作,尤其是 retrieval 与 ranking 联合优化。第二,关注多模态广告素材的扩展,因为论文 future work 提到 multimodal 和 real-time adaptive learning,而现实广告创意往往图文视频并存。第三,在自己的系统里把“语义等价变体稳定性”加入离线诊断,例如按标题改写、图片替换、商品同义类、品牌同义词构造 shadow pairs,先测出不稳定来源,再决定是否需要 LLM 召回路。总体上,这篇论文不是给出一个可直接照搬的开源方案,而是提供了一套把 LLM 语义能力接入广告候选生成、并用可预测性指标验证收益的系统方法。