RPORec:Reinforced Preference Optimization for Reasoning-Augmented Recommendations
这里精读一篇 2026-05-21 公开在 arXiv 的论文《Reinforced Preference Optimization for Reasoning-Augmented Recommendations》。中文可以叫《面向推理增强推荐的强化偏好优化》。论文链接:arXiv:2605.21967。作者为 Jingtong Gao、Zeyu Song、Chi Lu、Xiaopeng Li、Derong Xu、Maolin Wang、Peng Jiang、Kun Gai、Qingpeng Cai、Xiangyu Zhao;机构/团队为 City University of Hong Kong 与 Kuaishou Technology。代码/项目页本轮未核验到独立仓库。本地 PDF 为 多校-RPORec.pdf。
RPORec 关注 LLM4Rec 里一个常被低估的问题:显式 reasoning 不能只作为可读解释存在,它还要转化成可检索、可排序、可验证的推荐信号。论文把 LLM backbone 和专门的 recommendation head 连接成两阶段闭环,让 CoT 先帮助推荐表征学习,再让推荐头反过来提供 reward 优化 LLM reasoning。
1. 背景和问题
LLM 进入推荐系统后,最自然的想法是让模型读用户历史、生成推理过程,再输出推荐 item。这个方向看起来有吸引力,因为 LLM 具有上下文理解、世界知识和显式 Chain-of-Thought 能力,理论上可以解释用户为什么喜欢某类商品、如何从历史偏好迁移到新 item、以及不同属性之间有什么语义关系。但推荐任务并不只需要自然语言解释,它最终要在大规模候选集合中找出具体 item。自由文本 reasoning 与 item retrieval 之间存在结构落差。
已有 reasoning-based recommendation 大致有两类。第一类把 LLM hidden states 和推荐模块联合训练,希望在端到端优化里同时获得 reasoning 与预测能力;问题是推荐目标会直接扰动 LLM 内部状态,显式 CoT 质量和可解释性可能被削弱。第二类让 LLM 生成推荐文本或 semantic ID,即使保留了 reasoning,也要面对自由生成和精确 item 匹配之间的错配,尤其是训练未出现 item 或候选规模很大时,生成式输出很难稳定落到可排序空间。
RPORec 试图把这两个难点拆开:用 Rechead 负责精确 item retrieval,用 LLM backbone 负责结构化 reasoning。CoT 不直接作为最终答案,而是作为辅助知识进入推荐头;推荐头也不只是一个附属分类器,而是能产生可验证 reward,反过来对 LLM reasoning 做强化偏好优化。这样设计的目标是保持 LLM 的显式推理,同时让推荐目标有独立、稳定、可评估的建模入口。
从工业推荐视角看,这个问题非常实际。线上推荐通常不能让大模型直接阻塞毫秒级排序链路,也不能接受模型输出一个无法映射到库存 item 的自然语言标题。更可行的方式是把 LLM 放在 nearline 或离线用户理解位置,生成可缓存的用户兴趣、偏好线索或 CoT 表示,再让在线 ranking model 消费这些信号。RPORec 的价值就在于它既讨论了离线训练框架,也给出了 nearline/online 分工的系统图。
2. 方法
2.1 两阶段设计:Rechead 与 LLM backbone
RPORec 包含两个阶段。Stage I 是 Reasoning-Augmented Recommendation Modeling:先从 LLM 获得用户历史、CoT 和答案片段,再让 Rechead 学习把这些文本线索映射成推荐任务需要的 item 表征和预测。Stage II 是 Advanced Reasoning Refinement and Alignment:训练好的 Rechead 变成 reward source,用于 GRPO 风格的强化学习,优化 LLM backbone 生成的 reasoning,使其更贴近推荐目标、结构更稳定、任务相关性更强。
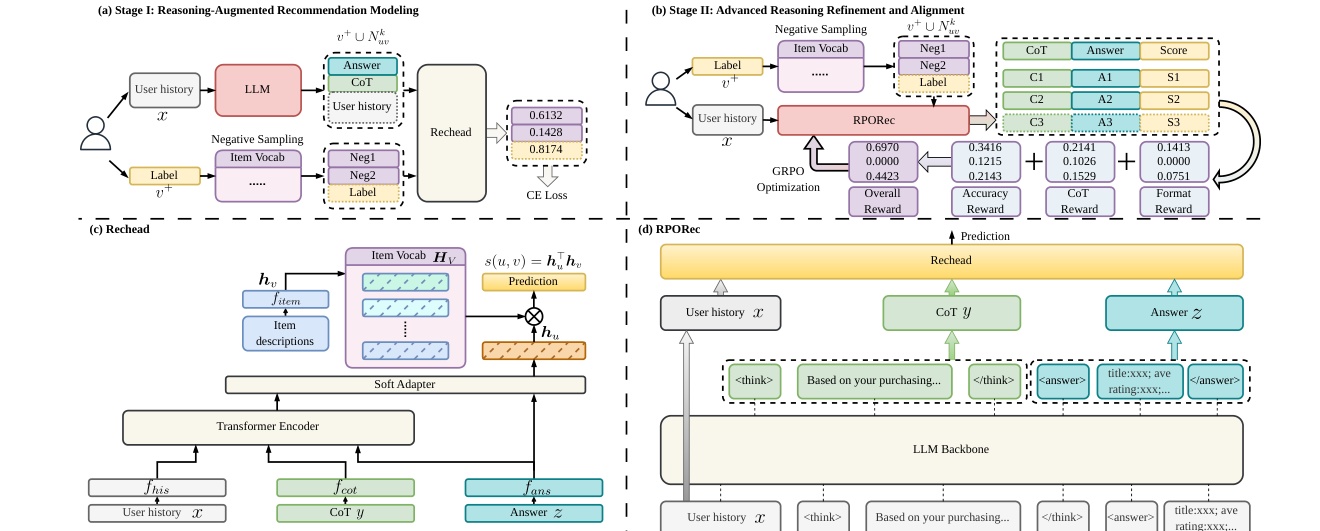
Figure 1(原文图 1)把 RPORec 的四个关键部件放在一起。左上和右上分别表示 Stage I 与 Stage II 的优化过程,中间的 Rechead 负责把用户历史、CoT 和最终答案编码成推荐表征,右侧的整体结构则展示 LLM backbone 与 Rechead 如何形成闭环。读图时最重要的是区分两种信号:LLM 生成的 CoT 提供语义和推理线索,但最终 item 预测由 Rechead 以推荐任务方式建模;Rechead 训练好之后又为 LLM 提供 reward,避免 RL 只围绕语言流畅度或泛化偏好打转。这个结构比“让 LLM 直接输出 item”更接近真实系统,因为 item retrieval 需要可计算、可批量、可评估的向量或得分空间。
2.2 Rechead 如何利用 CoT
Rechead 接收用户历史、推理链和答案文本。论文描述中,文本通过编码函数转换为表示,再与推荐任务目标结合。CoT 的作用不是替代用户历史,而是提供更细粒度的偏好解释,例如用户为什么从某些历史 item 迁移到候选 item、哪些属性在决策里更重要、哪些表面相似但偏好不匹配。这样的表示可以缓解纯序列模型只看 ID 转移的问题,也能减少纯生成模型无法稳定命中 item 的问题。
这里的工程关键是防止 CoT 噪声污染推荐头。如果 LLM 生成的理由冗长、重复元数据或包含虚构偏好,Rechead 可能学到错误的辅助信息。RPORec 因此在第二阶段引入 reward,对 CoT 质量、结构一致性和推荐任务相关性做进一步对齐。这个闭环使 CoT 不再只是训练样本里的附加文本,而是受到推荐指标约束的中间表示。
2.3 GRPO 对齐与 reward 设计
第二阶段使用 GRPO 类强化学习。与一般语言任务不同,推荐 reasoning 的 reward 不能只看格式或答案是否通顺,还要看它是否帮助推荐头给出更准确 item 预测。论文把 Rechead 训练成可验证组件后,再用它产生 reward。这样做的好处是 reward 与推荐目标一致,缺点是 reward 的可靠性依赖 Rechead 本身。如果 Rechead 在某些长尾 item、冷启动用户或跨域偏好上有偏,RL 可能放大这种偏差。
2.4 线上部署:nearline LLM 与在线 ranking 的分工
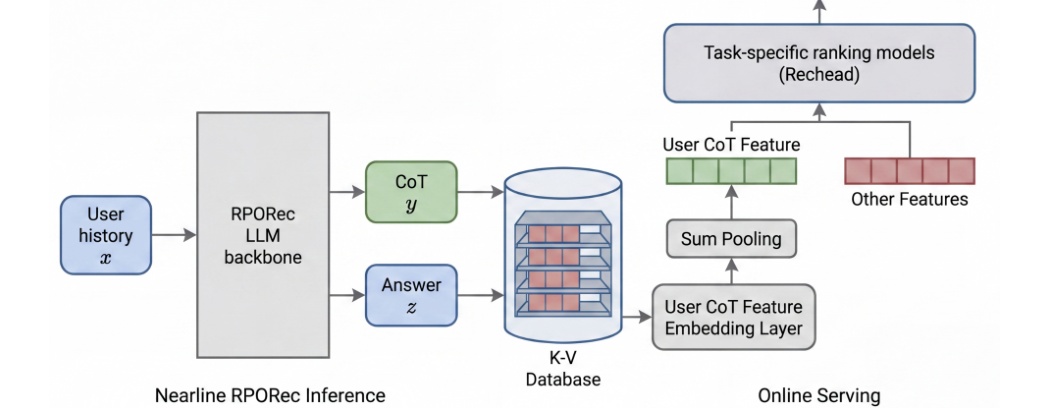
Figure 5(原文图 5)展示 RPORec 的线上部署方式。LLM backbone 位于 nearline 侧,输入 user history 后生成 CoT 和 answer 表示,并写入特征或 KV 数据库;在线 serving 侧由 ranking model 或 Rechead 消费这些用户 CoT 特征,同时结合 sum pooling、user CoT feature embedding layer 和其他在线特征。这个图说明论文并不主张把 LLM 放进实时排序主路径,而是将高成本 reasoning 前置到 nearline 用户理解模块。对工业系统而言,这个分工很关键:LLM 可以提升语义理解和偏好解释,但在线排序仍要满足延迟、吞吐、特征交互和可回滚要求。若没有这种拆分,LLM4Rec 的离线效果很难真正进入大规模广告或内容推荐场景。
3. 实验结果
3.1 设置与指标
实验使用三个 Amazon 数据集:Musical Instruments、CDs and Vinyl、Video Games。指标包括 H@5/10/20 和 N@5/10/20,用来评估 top-K 命中和排序质量。论文比较传统序列推荐、LLM 推荐、RL 型基线以及 RPORec 变体,并报告统计显著性。它还补充了 backbone 泛化、ablation、case study 和在线应用部分,试图证明方法不仅是一个离线 benchmark 技巧。
3.2 离线推荐结果
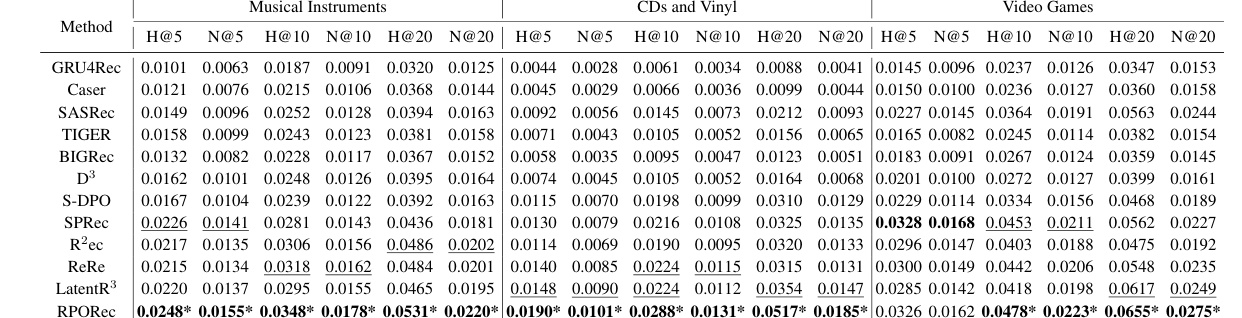
Table 1(原文表 1)是 RPORec 的主结果表。它按三个数据集列出 H@5、N@5、H@10、N@10、H@20、N@20,比较 GRU4Rec、Caser、SASRec、TIGER、BiRec、DPO、SPO、RLRRec、ReRe、LatentR3、LLaRA 等方法。RPORec 在多个指标上位于最优,并用显著性标记表示相对次优方法的差异。表格最值得关注的是 small LLM 场景下仍能通过结构化推荐头取得收益,而不是单纯依赖模型规模。H@K 提升说明候选命中更好,N@K 提升说明命中 item 的排序位置也更靠前;如果只提升 H@20 而 N@5 不动,说明方法可能只是扩大候选覆盖,RPORec 的结果更像是同时改善了候选识别和排序质量。
3.3 消融、推理质量与在线验证
论文还给出 ablation,说明移除 CoT-aware modeling、移除 Stage I、移除 Stage II 或不对 reward 做细分都会影响结果。Case study 观察到缺少 CoT reward 时,模型容易生成冗长、重复元数据或与推荐相关性弱的 reasoning;加入 reward 后,推理更聚焦于用户偏好和候选关系。在线部分则显示 RPORec 被集成到快手广告推荐链路中,作为 nearline user understanding 组件服务后续 ranking。公开文本对线上指标做了归一化或相对描述,因此不能把它当成可完全复现的线上绝对收益,但它足以证明作者关注真实部署约束,而不仅是离线表格。
3.4 如何解读在线部署证据
RPORec 的在线应用部分容易被误读为“大模型直接上线排序”。Figure 5 和文字描述实际上说明,LLM backbone 主要放在 nearline 侧生成用户理解与 CoT 特征,在线 ranking model 才承担实时打分。这意味着论文的工业价值不在于证明 LLM 可以替代排序模型,而在于展示 reasoning 信号如何被缓存、特征化并供在线模型消费。公开文本提到大规模广告系统和相对收益,但没有暴露完整流量切分、延迟预算、特征刷新周期、线上指标定义和绝对业务量。因此读在线结果时应保守:它能证明方法具备工业接入形态,不能直接证明任何平台都能复现同等收益。
4. 总结
4.1 我的判断
RPORec 的最大价值是把 LLM reasoning、推荐表征和线上部署三件事放在同一个框架里。它没有让 LLM 直接承担所有推荐决策,而是承认推荐任务需要专门的 item retrieval head;它也没有把 CoT 当成纯解释文本,而是让 CoT 进入 Rechead 并接受推荐目标反馈。这个结构比“LLM 生成推荐理由”更有工程含义。
可能被高估的是 RL 部分的泛化能力。Rechead 作为 reward source 很实用,但如果训练数据、item 分布或用户行为存在偏差,reward 会继承这些偏差。GRPO 对齐可能让 reasoning 更符合当前数据集,却未必能在跨域、冷启动或强实时反馈环境下保持稳定。因此复现时不能只看最终 Hit/NDCG,还要检查 reasoning 是否真的更短、更准、更少幻觉。
4.2 工程启发与复现建议
最小复现可以从三个层级做。第一层只训练 Rechead,输入用户历史、候选 item 文本和 LLM 生成 CoT,验证 CoT 是否提高 H@K/N@K。第二层加入 reward,对 LLM 生成的 CoT 做轻量 RL 或偏好优化,观察推理质量和推荐指标是否同步改善。第三层再模拟 nearline/online 分工,把 LLM 输出缓存为用户特征,测试在线 ranking 模型消费这些特征时的延迟、覆盖和稳定性。
上线前要特别关注特征过期和反馈闭环。用户兴趣变化后,nearline CoT 如果刷新不及时,可能比传统短期行为特征更滞后;如果 ranking model 过度依赖 CoT,又可能把 LLM 的错误解释放大到曝光分配里。建议同时监控特征新鲜度、长尾 item 覆盖、reasoning token 长度、P95 特征读取延迟和线上 A/B 的分层收益。
4.3 局限与后续跟进
局限方面,第一,公开论文未核验到独立代码仓库,复现训练细节需要自行实现。第二,Amazon 数据集与工业广告系统之间有分布差异,离线商品推荐指标不能直接代表广告投放收益。第三,CoT reward 可能优化出更符合 Rechead 偏好的推理,但未必等同于真实用户偏好解释。第四,nearline LLM 特征会带来成本、刷新频率、隐私字段和缓存一致性问题,论文没有完全展开这些工程约束。
后续跟进应优先看三点:一是作者是否公开训练脚本、reward 细节和在线部署更多指标;二是 RPORec 在非 Amazon、非英文或多模态推荐场景下是否仍能稳定提升;三是 CoT 质量是否可以用人工评估、反事实删除或用户行为反证进一步验证,避免只用推荐指标间接推断 reasoning 变好。
4.4 与其他 LLM4Rec 路线的差别
RPORec 和纯 prompt-based recommender、semantic ID 生成、LLM reranker 有明显差别。Prompt-based 方法实现简单,但很难保证大候选集合里的精确命中;semantic ID 生成可以把 item 映射进 token 空间,却仍然面对新 item 和生成稳定性问题;LLM reranker 通常成本高,只适合很小候选集。RPORec 把 LLM 的作用集中在 reasoning 表征和 nearline 用户理解,再让 Rechead 承担推荐头职责,属于更工程化的折中路线。它的关键风险也来自这个折中:如果 CoT 特征刷新慢或 reward 与真实业务目标不一致,系统可能得到一个看似有解释、实际偏离用户即时意图的中间表示。