Search-E1:Search-E1: Self-Distillation Drives Self-Evolution in Search-Augmented Reasoning
这里精读一篇 2026-05-21 公开在 arXiv 的论文《Search-E1: Self-Distillation Drives Self-Evolution in Search-Augmented Reasoning》。中文可以叫《自蒸馏驱动搜索增强推理智能体自进化》。论文链接:arXiv:2605.22511。作者为 Zihan Liang、Yufei Ma、Ben Chen、Zhipeng Qian、Xuxin Zhang、Huangyu Dai、Lingtao Mao;论文首页未清晰列出统一机构,本轮按多校/团队记录。代码/项目页本轮未核验到独立仓库。本地 PDF 为 多校-SearchE1.pdf。
Search-E1 试图回答一个很直接的问题:搜索增强推理模型能否不依赖外部强教师、过程奖励模型或复杂树搜索,只用自己的 sibling rollout 做自蒸馏,从而学会更有效的搜索路径。它适合放在 RAG agent、搜索增强问答和推荐式交互检索训练里一起看。
1. 背景和问题
搜索增强推理模型通常需要在生成过程中调用搜索引擎、阅读证据、整合信息并输出答案。相比普通问答,它的难点不只是语言生成,而是何时搜索、搜索什么、如何使用证据以及何时停止。近年的方法常加入过程奖励模型、强教师蒸馏、树搜索、retrospective critic 或复杂 reward shaping。这些组件可以提升能力,但也带来高训练成本、外部依赖和实现复杂度。
Search-E1 的问题设定更朴素:如果同一个模型对同一个问题采样多条搜索轨迹,其中有的轨迹更短、更有效或命中答案,有的轨迹冗长或失败,那么这些 sibling trajectories 之间的差异能否成为训练信号?模型是否可以从自己产生的更好路径中学习,而不是每一步都依赖外部教师?这个思路被论文称为 self-evolution,但它不是无监督自学;它仍然依赖问答数据、exact-match outcome reward 和固定搜索协议,只是把改进信号更多地来自模型自身 rollout。
这个问题和推荐/搜索系统也有关。交互式推荐、商品搜索 agent 和 RAG 问答都需要探索候选、读取证据和组合上下文。若模型能从自己的多路径探索中学会更高效地检索和停止,类似思想可以迁移到推荐解释、候选探索和用户意图澄清中。关键是 reward 设计必须和任务一致:标准 QA 可以用 EM,推荐场景则可能需要候选覆盖、用户反馈、解释忠实性和交互成本共同定义。
2. 方法
2.1 GRPO 与 OFSD 交替训练
Search-E1 由两个交替阶段组成。第一阶段是 GRPO round,模型在固定搜索引擎下生成多条轨迹,并根据最终答案的 exact-match outcome reward 得到组相对优化信号。这个阶段负责探索:模型尝试不同搜索、阅读和回答路径。第二阶段是 Offline Self-Distillation,也就是 OFSD:从同题 sibling rollout 中选择更有信息的 reference trajectory,让 student 在普通上下文下学习 privileged teacher 在多看到参考轨迹时的 token 分布。
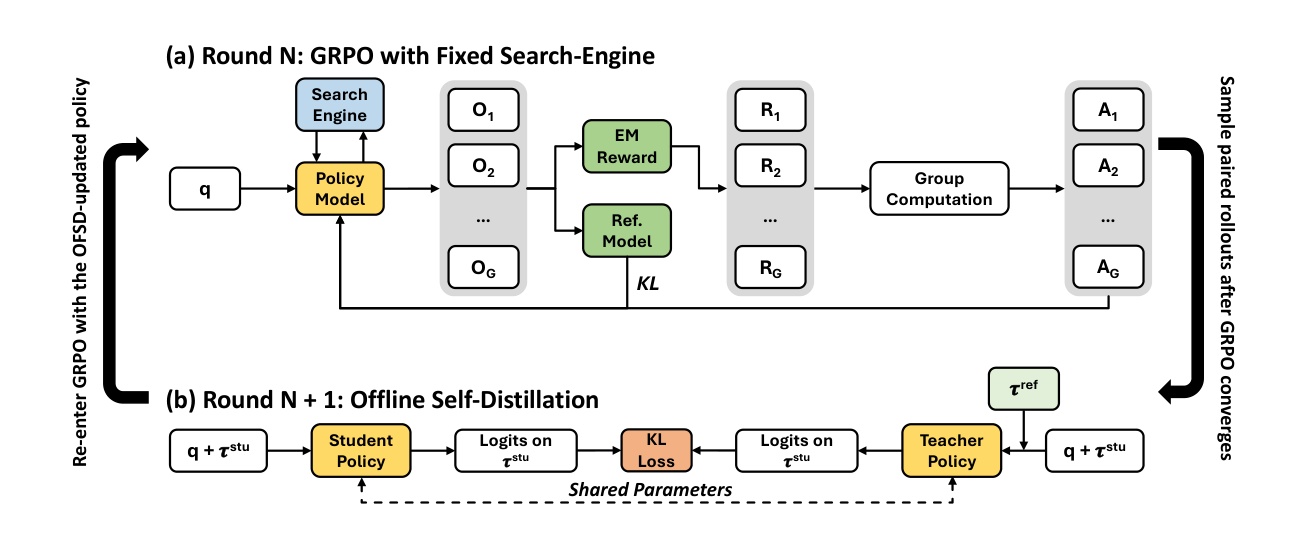
Figure 1(原文图 1)上半部分是 GRPO round:问题 q 经过 policy model 产生多个输出和搜索结果,EM reward 与 reference model 共同参与 group computation,形成强化学习更新。下半部分是 OFSD round:student policy 只看到 q 加自身轨迹,teacher policy 多看到参考轨迹,二者共享参数但条件不同,在学生生成位置上做 distillation。图的重点是两个阶段分工清楚:GRPO 负责让模型在任务 reward 下探索,OFSD 负责把同题更好路径的信息压回普通推理条件。这样可以减少对外部强教师和过程奖励模型的依赖。
2.2 Offline self-distillation 的 token-level 对齐
OFSD 的核心不是复制参考答案,而是让学生在生成过程中靠近带 privileged context 的教师分布。参考轨迹来自同一问题的 sibling rollout,可以是更有效、更接近答案或信息更充分的路径。教师条件包含 q、参考轨迹和学生轨迹,学生条件只包含 q 和学生轨迹。训练目标使用 token-level forward KL,让学生在没有额外参考上下文时,也倾向于产生更接近教师的搜索与推理分布。

Figure 1(b) detail(原文图 1 下半部分)放大了 OFSD 的信息结构。student policy 输入 q 加当前学生轨迹,teacher policy 输入 q、参考轨迹和当前学生轨迹,二者在 logits 上对齐,KL loss 只作用在学生生成位置。这个设计比直接蒸馏最终答案细,因为搜索增强推理的价值往往在中间步骤:先搜哪个实体、是否需要第二次搜索、如何把两个证据片段合并、什么时候停止。forward KL 让学生学习这些过程偏好,但不会在推理时要求额外 reference trajectory。
2.3 为什么交替而不是一次性蒸馏
如果只做 GRPO,模型能根据最终答案得到奖励,但多跳搜索中的 token 级错误很难被定位;如果只做蒸馏,模型可能受限于已有轨迹,缺少新的探索。Search-E1 交替两者:GRPO 产生新 sibling rollout,OFSD 从这些 rollout 中抽取可学习差异,再将其压回 policy。这个循环的工程好处是模块化,训练失败时可以分别检查探索阶段和蒸馏阶段,而不是把所有复杂信号混在一个 loss 里。
3. 实验结果
3.1 训练和评测设置
论文遵循 Search-R1 协议,训练数据结合 Natural Questions 与 HotpotQA,约 170k question-answer pairs。评测包括三个单跳 QA 数据集 NQ、TriviaQA、PopQA,以及四个多跳 QA 数据集 HotpotQA、2WikiMultihopQA、MuSiQue、Bamboogle,共覆盖七个 benchmark。主指标是 Exact Match,并采用标准 normalization。模型设置中报告了 Qwen2.5-3B 场景。
3.2 七个 QA benchmark 主结果
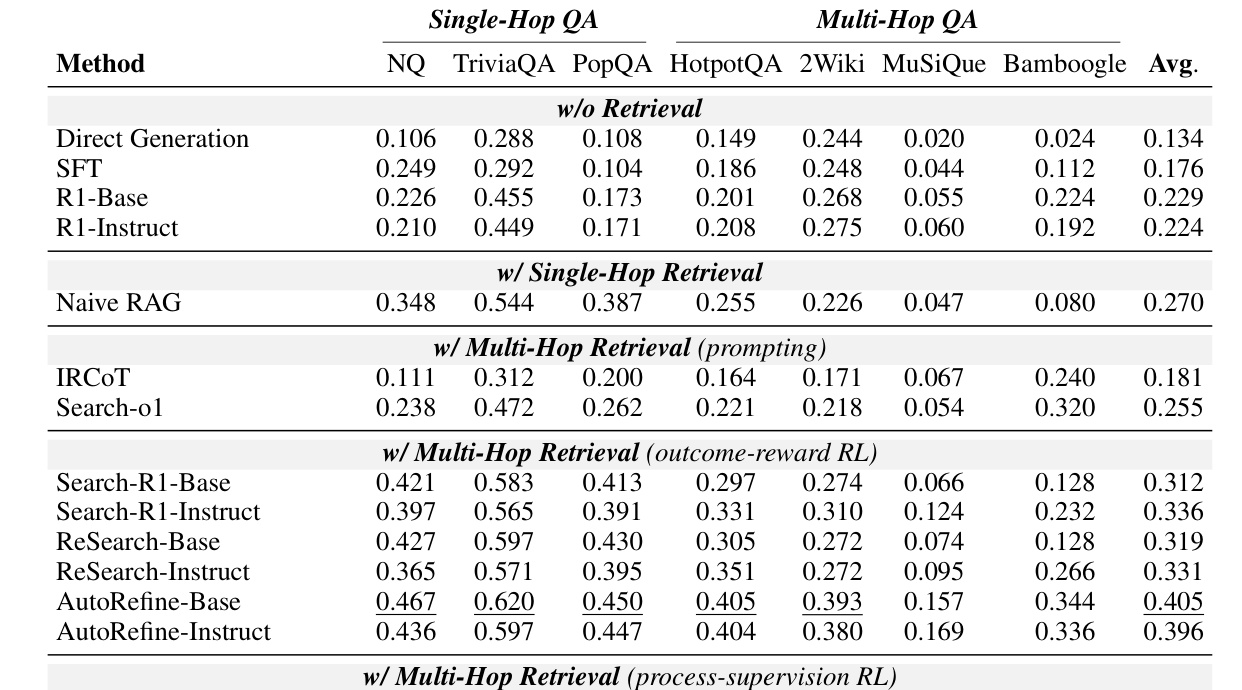
Table 1(原文表 1)按单跳、多跳和平均值列出多种方法的 EM。Search-E1 在 Qwen2.5-3B 设置下平均 EM 为 0.440,高于 AutoRefine-Base 的 0.405,也高于若干 outcome-reward baseline。表格还显示多跳任务上的收益更明显,例如 HotpotQA、2Wiki、MuSiQue、Bamboogle 等需要组合多个证据的场景。这与方法假设一致:单跳问题中搜索路径差异较小,sibling rollout 可提供的信息有限;多跳问题中不同检索顺序和证据组合会造成更大差异,OFSD 更容易从好路径中提取 token-level 学习信号。表中也要注意,EM 只衡量答案字符串是否命中,不能完全证明模型使用了忠实证据。
3.3 结果解释与可复现风险
论文将 Search-E1 与直接生成、SFT、RI-base、RI-instruct、Naive RAG、IRCoT、Search-R1、ReSearch、AutoRefine 等方法比较。这样的比较能显示 OFSD 对 outcome-reward RL 的补充作用,但复现时仍有几个敏感点:搜索引擎固定、检索语料和查询格式会影响结果;sibling trajectory 的选择标准会影响教师质量;forward KL 权重、GRPO round 与 OFSD round 的调度会影响训练稳定性。若这些细节不同,平均 EM 的提升幅度可能变化很大。
3.4 多跳收益为什么更关键
Search-E1 在多跳任务上的收益比单跳更值得关注。单跳 QA 往往只需要一次检索就能找到答案,模型的主要挑战是识别正确实体和抽取答案;多跳 QA 则需要先找到一个桥接实体,再围绕它进行第二次或第三次检索,还要组合多个证据片段。Sibling rollout 在这种场景里差异更丰富:有的轨迹先搜错实体,有的轨迹找到第一跳但没有继续,有的轨迹检索到了证据却过早回答。OFSD 正是利用这些路径差异,把更有效的搜索顺序和停止策略蒸馏回来。因此若复现只在单跳数据上看平均 EM,可能低估方法价值;若迁移到推荐,也应该优先选择需要多步候选探索的任务,而不是一次检索即可解决的场景。
4. 总结
4.1 我的判断
Search-E1 的贡献在于把搜索增强训练中的复杂组件做了减法。它不依赖强外部教师,也不需要专门训练过程奖励模型,而是利用同一模型在同一问题上的多路径差异。这个想法很适合资源受限但能离线采样多条轨迹的团队。它也提醒我们,搜索增强 reasoning 的训练信号不一定只能来自人工标注或外部大模型,模型自身 rollout 中已经包含可比较的好坏路径。
但“自进化”不能理解得过宽。Search-E1 仍然有答案监督、固定搜索协议和 EM reward;它不是在开放世界中无监督提升。换到推荐、开放式问答或多答案任务时,如何定义更好 sibling trajectory 会成为核心问题。如果 reward 不稳定,OFSD 可能会把错误路径蒸馏得更自信。
4.2 工程启发与复现建议
复现路径可以从小模型和固定检索器开始。先按 Search-R1 协议跑 GRPO,保存每个问题的多条 trajectory、搜索查询、检索文档、最终答案和 EM。然后设计 sibling pair mining:优先选择答对、搜索步数更少、证据覆盖更好且无明显无关文档的轨迹作为 reference。最后加入 OFSD,观察多跳 EM、平均搜索步数、证据引用覆盖和无效检索次数是否改善。
如果迁移到推荐或商品搜索 agent,可以把 sibling rollout 定义为同一用户意图下的多条候选探索路径。更好的路径不一定是“答对”,而可能是覆盖更多相关候选、解释更短、用户反馈更好或调用成本更低。需要把 reward 从 EM 改成任务相关指标组合,并增加反事实检查,避免模型学会少搜或乱搜但碰巧命中离线标签。
4.3 局限与后续跟进
局限方面,第一,EM 不能充分衡量证据忠实性,模型可能答对但检索路径并不可靠。第二,方法需要同题多条 rollout,离线采样和搜索调用成本会随样本数上升。第三,固定搜索引擎下学到的策略可能无法迁移到不同检索器、不同语料或实时变化的网络环境。第四,论文未核验到独立代码仓库,OFSD pair mining、KL 权重和训练调度细节需要等待实现确认。
后续跟进应关注三点:一是作者是否公开代码和 Search-R1 兼容脚本;二是 Search-E1 与过程奖励模型、树搜索和外部教师蒸馏在成本收益上的直接比较;三是加入 evidence fidelity、引用覆盖和检索步数指标,确认 EM 提升是否来自更好的搜索路径,而不是仅仅来自答案模式记忆。
4.4 失败模式和监控指标
Search-E1 上线到搜索 agent 或 RAG agent 前,需要为失败模式设计指标。第一类是检索不足:模型为了减少步骤而少搜,答案看似简洁但证据缺失。第二类是检索漂移:模型从 sibling trajectory 学到某些常见搜索模板,遇到长尾问题时反而走向无关实体。第三类是蒸馏过度:student 过分模仿 privileged teacher 的分布,但推理时没有 reference context,导致生成自信却不可验证的中间结论。第四类是 reward hacking:EM reward 只看答案字符串,模型可能学会从训练分布猜答案而不是真正使用搜索。监控时应同时记录搜索次数、检索文档命中、引用覆盖、答案 EM、人工证据忠实性和失败问题类型。
4.5 与推荐候选探索的类比
推荐系统中的候选探索也有 sibling rollout。对于同一用户意图,可以先按历史行为检索,也可以按语义标签检索,还可以按相似用户或热门趋势扩展。不同路径可能得到不同候选集合和解释。Search-E1 的思路提示我们,可以离线采样多条候选探索路径,选择覆盖真实正例更多、路径更短、解释更可读或用户负反馈更低的路径作为 reference,再训练推荐 agent 在普通输入下更接近这些路径。但推荐没有唯一答案,reward 要比 QA 更复杂,必须把覆盖、排序、成本和用户反馈合在一起。
4.6 对训练数据和搜索协议的依赖
Search-E1 的结论还依赖 Search-R1 协议、NQ/HotpotQA 训练分布和固定搜索引擎。训练集约 170k 问答给了模型足够多的同题采样空间,但也意味着方法的自蒸馏质量受数据覆盖影响。如果训练问题较简单,sibling rollout 差异不大,OFSD 可学习信号会弱;如果训练问题噪声大,reference trajectory 选择错误,蒸馏会把错误搜索偏好压回模型。固定搜索引擎也会塑造策略:模型可能学会适配某个检索器的返回排序和片段风格,换成另一个搜索后需要重新校准。实际工程复现时,应该把搜索协议视为模型的一部分,记录检索器版本、top-K、query rewrite 规则、文档截断方式和答案匹配口径,不能只记录基础模型和 RL 超参。
4.7 与过程奖励模型的取舍
相比过程奖励模型,OFSD 的优势是实现轻量、外部依赖少,并且能利用模型自身产生的多样路径;缺点是监督信号间接,无法像人工过程标注那样明确指出哪一步搜索错误。过程奖励适合高价值、可标注、失败代价高的任务,OFSD 更适合可以大量离线采样、答案 reward 相对清楚、搜索成本可控的任务。一个务实方向是先用 Search-E1 式自蒸馏获得基础搜索策略,再在少量关键任务上加入人工或模型评审的过程奖励,检查两者是否互补,而不是一开始就把所有训练复杂度堆满。